What we've shipped
A running log of SideQuest releases. Connector version bumps, new docs, site updates, reliability fixes. We update this every time something noteworthy ships.
Your dashboard snapshot now reads like a back office instead of one long scroll. Same numbers, far less hunting.
- Sidebar navigation. A fixed left rail lists every section (Overview, Review queue, Customer health, Pricing, Catalog, Activity) and highlights where you are as you scroll. Jump straight to the part you need.
- Dark mode. A toggle in the top bar flips the whole dashboard, every card and chart included. It remembers your choice and follows your system setting the first time you open it.
- Grouped, collapsible sections. The big insight panels (review queue, customer health, pricing, catalog) sit under section headers and collapse on click, so you can fold away what you are not looking at.
- Still one file, still offline. The dashboard is the same self-contained HTML you open from disk. No account, no internet, no data leaving your machine. The raw-data export is unchanged.
The numbers, the reports, and how they are calculated did not change. This is the frame around them. Regenerate the dashboard after installing to see the new layout.
A customer emails a revised PO. Now you get one flagged estimate with the changes called out, instead of a second estimate you have to hunt down and reconcile by hand.
- Revised POs get flagged, not duplicated. When a PO number you have already drafted arrives again on a new email, SideQuest stops and shows you what changed: lines added, lines removed, quantity changes, and price changes, with the old and new order totals side by side. You choose whether to replace the original estimate or keep both. Before this, a revised PO quietly became a second draft, and catching the mismatch was on you.
- The same email twice no longer doubles up. Re-processing a PO email you already drafted returns the estimate you have instead of building a copy. If you discarded that draft on purpose, re-processing rebuilds it fresh.
- Replacing a PO is safe. When you supersede an original with its revision, SideQuest cross-links the two so the trail is clear. It refuses to supersede an estimate that already went to QuickBooks, so your books never drift out of sync behind your back.
- Clearer messages when an input is off. Mistype a report period and SideQuest names the periods you can use. Point it at an empty email and it tells you up front instead of spending a step to fail. A few operations that used to show a generic code now say what to fix.
Re-keying revised POs is one of the most common ways a wrong estimate reaches a customer. This closes that gap. No new setup, no new settings, nothing changes about how you review and confirm drafts.
Building the Odoo sister connector earned its keep. Two bugs that lived in production QBO code for months — both masked by downstream rescue paths — surfaced when the Odoo hermetic CI exercised the same logic without the rescues. Both are now closed in QBO too.
- Parser column precedence —
customer_partsilently set to a description string instead of the real SKU on a class of PDFs. When a PO PDF's part column used an unrecognized header (e.g., "Supplier Ref", "Manufacturer Code"), the generic"item"keyword at the end of the SKU allowlist in_find_column_indiceswould match an "Item Description" column instead. Result: the parser correctly identified column count but routed the description string intocustomer_part. In QBO this stayed invisible because the LLM extraction pass downstream usually rescued the PO — but the parser-stagecustomer_partwas still wrong, so the cross-reference flywheel never accumulated a real(customer_part → internal_sku)rule for those customers. Customers running these PO shapes saw a flywheel that "just never seemed to learn." The Odoo connector (no LLM rescue layer yet) caught this immediately on its first hermetic integration run. Fix:_find_column_indicesnow resolves the description column FIRST, then passes its index to the part-finder'sexcludeset so the"item"fallback can never alias to it. Four new regression tests intest_parser_text_shapes.pylock the behavior across header shapes. - Money quantization —
update_qb_item_priceechoed float-repr noise back to the operator. QB storesItem.UnitPriceas a float internally. Writing 4.85 and reading it back can return 4.8500000000000005 over the wire — the same float-precision noise that bit the Odoo connector'supdate_odoo_product_priceon its first live run against a real Odoo. In QBO, the response's"new_price"field would surface that noise to whoever called the tool (operator, or Claude reading the response). Fix: the tool now quantizes the echoed price to cents withROUND_HALF_UP(operator-intuitive rounding — 4.855 → "4.86", not banker's rounding's "4.84") before stringifying. Four new regression tests intest_update_qb_item_price_guards.pycover the noisy-float path (using0.1 + 0.2 → "0.30"as a deterministic noise trigger), HALF_UP rounding, the clean-passthrough case, and zero pricing.
517 tests green (was 508 in v0.15.43 — added 4 parser precedence regressions, 4 money-quantization regressions, plus 1 already-pre-existing). No API breaks. No new env vars. Both fixes are pure boundary tightening — they cannot cause new failures, only stop a class of silent bugs.
Worth saying directly: this is the value of the two-product architecture. Every feature carried over to Odoo via the vendoring discipline gets re-exercised against a different backend in CI, and the differences in backend behavior surface latent assumptions the QBO test suite never had reason to question. Both these bugs lived in production for nine and seven releases respectively. The Odoo hermetic CI is now a permanent second pair of eyes on every shared core change.
The dashboard read "0 POs this month" while paying licenses were running real workloads. Three silent failures, all closed.
- Usage events never reached the control plane unless an operator ran the CLI manually. Pre-v0.15.43 the connector recorded every PO into
~/.qb-distributor-mcp/usage_log.sqliteas it happened, butflush_usage()only ran when someone explicitly typedsidequest flush-usage. No startup hook, no background loop. Customers processed POs all day; the control plane saw none of it.cmd_serve(the MCP server entry point that Claude Desktop spawns) now drains the usage_log on boot and then a daemon thread re-flushes every 30 minutes while the server runs. Stderr logs each flush ("sent N events" / "skipped — reason") so an operator watching verbose logs can see the heartbeat. - CLI subcommands ran without loading
.envfirst. Lazy imports inside each subcommand (from . import licensing) meantlicensing.pyreados.environbefore anything had loaded~/.qb-distributor-mcp/.env. Result:sidequest flush-usagereturned{"status": "skipped", "reason": "disabled_or_no_key"}on machines where the .env was correct and the license key was present. Same gate fired forsidequest doctorlicense-check output when env vars weren't pre-exported. Fix:cli.pynow eagerly importsconfigat module level so_load_dotenv_from_home()runs before any subcommand dispatches. - The combined "disabled_or_no_key" skip reason hid which gate fired. Pre-v0.15.43 the operator couldn't tell whether
QBD_CONTROL_PLANE_URL=disabledwas set orQBD_LICENSE_KEYwas missing — different bugs with different fixes, indistinguishable response.flush_usage()now returns one ofcontrol_plane_disabledorno_license_keywith a per-reasonhintfield that names the .env line to check and the next step. Same "every gate names itself" discipline as the v0.15.41 cross-reference flywheel rework.
508 tests green. No API breaks. No new env vars. The auto-flush layer is opt-out — set QBD_CONTROL_PLANE_URL=disabled in .env to keep usage strictly local (DEMO_MODE behavior unchanged).
Same-day P1 fix. A new-connector code review surfaced a real production bug the v0.15.X test suite had silently sidestepped for nine releases.
- QBItem.unit_of_measure field was missing from the schema while the matcher read it.
matcher._apply_uom_checkat line 357 readresult.qb_item.uom. The QBItem Pydantic model had nouomfield. Every PO line that carried a non-emptyline.uomAND successfully matched to a catalog item raisedAttributeError: 'QBItem' object has no attribute 'uom'at the catalog-UoM read. The parser populatesline.uomon any of the 9 packaging UoMs it recognizes (ea, bx, pk, cs, dz, gr, plt, drum, spool, tube) — added in v0.15.8 — so any real-world PO with a UoM blew up in production. - The test suite missed it because of a Pydantic
model_copytrick.tests/test_uom_catalog_verification.pyconstructed catalog items asQBItem(...).model_copy(update={"uom": uom})— that path sneaks the attribute in at instance level, bypassing schema enforcement. Every test passed while every production code path failed. The fix renames test fixtures to use the canonical schema field and adds a dedicated regression suite (tests/test_uom_field_no_attribute_error.py, 8 tests) that constructs QBItem normally — no model_copy hacks — and exercises the matcher's UoM check end-to-end. Any future model-vs-test divergence fails the build, not production. - Fix: added
unit_of_measure: str | None = NonetoQBItemas the canonical schema field. Matcher now readsqb_item.unit_of_measure. A read-only.uomproperty is kept as a back-compat shim for any external caller that hard-coded the short name.QBClient._to_modelpopulatesunit_of_measurefrom QBO'sUnitAbbreviationfield when the customer's QB account has the UoM feature enabled (most don't — field falls through to None, matcher short-circuits to ea-family fallback, prior behavior preserved). - How it surfaced: A new-build Claude vendoring
matcher.pyinto a sibling connector spotted the schema gap during code review and flagged it before touching the matcher in the new repo. Surfacing the bug at vendoring time, fixing upstream, and re-syncing is the discipline we want from every cross-codebase port going forward.
508 tests green (was 500 in v0.15.41 — added 8 new regression tests for the QBItem schema + matcher path).
Stop guessing why the flywheel skipped. Stop missing a release because no one told you. Bake the regression net.
- Auto-learn flywheel: every silent gate now names itself. Pre-v0.15.41
_autolearn_cross_referencereturned bareNoneat eight separate precondition gates (auto-learn disabled, free tier, no customer_qb_id, no original_customer_part, no qb_item_id, no CSV configured, qb_item_id not in catalog, already in index). When post-release QA hit "the flywheel didn't fire" the only diagnosis path was to instrument and re-ship. Now every skip returns{"skipped": true, "reason": "<slug>"}riding out onsubmit_estimate_to_qb'sautolearned_cross_referencekey. Behavioral diagnosis is one response-payload inspection away. - 10 new regression tests pin the flywheel end-to-end. v0.15.40's matcher-layer fix is provably correct in isolation: matcher construction, CSV roundtrip, live
add_cross_reference, customer_id int/str drift, customer_part whitespace drift, and global-alias paths all green. Future refactors that re-introduce the v0.15.40-class bug will fail at build time, not in production a week later. sidequest doctornow probes for newer releases. Fetcheshttps://sidequestautomation.com/latest-version.txtwith a 3-second timeout, compares to__version__, prints eitherLatest release: 0.15.42 ← you are behind. Upgrade with: ...(paste-ready 3-command upgrade) orLatest release: 0.15.41 ✓ up to date. Fail-quiet on every error class (404, empty body, garbage body, timeout, DNS error) — never blocks the doctor command on a network blip. HonorsSIDEQUEST_SKIP_VERSION_CHECK=1for paranoid ops teams.- 23 new regression tests pin the version probe. Cover every parse case (clean release, leading
v, pre-release suffix, build metadata, junk), every fail-quiet path (404, empty, garbage, timeout, network error), and the opt-out env var. Guarantees the probe stays additive — a transient marketing-site outage cannot breaksidequest doctor. - Pipeline funnel: vertical bars → horizontal funnel. Old vertical layout broke when one stage dominated (78 parsed, 0 drafted, 16 submitted, 0 discarded made the lone tall bar dwarf everything; floating "0" labels read as a layout glitch). New horizontal layout gives every stage equal vertical weight, value sits at a stable right-aligned position, bar length carries proportionality, empty stages render as a flat grey baseline. Reads cleanly even when most stages are zero.
- Dashboard now has time-period filter chips. One offline HTML file, seven periods baked in: Last 24 hours · Past week · Last month · Last 3 months · Last 6 months · Quarter to date · Last year. Click a chip, the dashboard switches periods instantly — no re-run, no second render. Selection persists in
localStorageso re-opening the same file keeps your last view. Each period block renders independently so a single report failure on one period doesn't taint the others. Reporting layer'sVALID_PERIODSset was extended additively to accept1d,90d,180d,qtd,1yon top of the existingall / today / 7d / 30d / mtd / ytd— strictly additive, every existing report call keeps working. QTD aligns to the calendar quarter start (Jan/Apr/Jul/Oct day 1). - Top Items + Top Customers tables: sortable + searchable. Click any column header to sort asc/desc (SKU, qty, revenue on items; customer, POs, revenue on customers). Sort uses the underlying numeric value, not the formatted string, so "$92,117.97" sorts correctly against "$1,234.56". Each table has a substring search box at the top — type "SAW" to filter to recip saws, type "Contractor" to scope to one customer. All client-side JS, no backend round trip.
Privacy posture preserved: the probe is a pure GET on a static text file. No telemetry, no install fingerprint, no machine ID. The marketing-site origin sees the same payload a homepage visitor sees.
500 tests green. No API breaks. No new env vars. Site stamp on /features advances to v0.15.41.
External QA's deep probe round surfaced six findings. Three were P0 safety-gate bypasses and a P0 flywheel bug. All six ship in this release.
- Cross-reference auto-learn flywheel was half-broken (P0). Rules WERE being written to the CSV correctly. But the next session's matcher never APPLIED them — yesterday's auto-learned
MYSTERY-SKU → DM78123for customer 58 came back as unmatched today. Root cause: the CSV storedcustomer_idas a string "58"; the MCP caller passed integer 58 throughmatch_po_lines; the lookup key mismatched. Pre-fix, every cross-session lookup quietly missed. Now:_normalize_customer_id()coerces both sides at every boundary (CSV load, in-memory add, has-check, match-time lookup). The flywheel actually compounds across sessions. - auto_submit_if_clean(override_clean_gate=true) used to bypass SIDEQUEST_AUTOSUBMIT (P0). The gate was
if not _autosubmit_enabled() and not override_clean_gate:— a logical AND. Settingoverride_clean_gate=truesilently defeated the master safety switch. Now the env gate is checked independently;override_clean_gateonly relaxes the per-draft quality check. - bulk_submit_clean had NO SIDEQUEST_AUTOSUBMIT gate at all (P0). An operator with the safety switch off could call
bulk_submit_clean(confirm=True)and mass-submit every clean draft to live QB. Full back-door around the documented contract. Now the same env gate applies;dry_run=Truestill works without the env var so operators can preview. - run_ar_followup_sweep ignored its documented SIDEQUEST_AR_FOLLOWUP gate (P1). Docstring + setup health check both promised the gate; the function body never checked it. Paid-tier operators with the switch off were silently getting Gmail drafts written. Now gated;
dry_runpreview still works without the env. - add_draft_line accepted non-existent qb_item_id silently (P2).
qb_item_id=99999succeeded — a phantom reference lived on the draft until QB submit-time failed. Now the qb_item_id is verified against the local catalog before storing;qb_item_id=None(name-only lines) still works. - auto_submit_if_clean leaked raw QB ValidationException unwrapped (P2). Stack-trace strings escaped instead of the typed error envelope used elsewhere. Now wrapped as
{"error": "qb_validation_failed", "exception_type": "...", "message": "..."}.
One more piece of structural hygiene: introduced _env_flag_enabled() as the shared opt-in checker for AUTOSUBMIT, AUTOACK, and AR_FOLLOWUP. Three tools used to re-implement the truthy set inline — when AUTOACK got it right and AR_FOLLOWUP forgot to check at all, the inconsistency was the bug. One helper, one truth, no drift.
460 tests green. No API breaks, no new env vars.
Previous releases
Click any version to expand. Newest first.
v0.15.39 P0 catch — update_qb_item_price("0") no longer lies; attachment_count actually works; --version flag added June 5, 2026
Same-day patch. External QA retested v0.15.38, caught one P0, and surfaced three things v0.15.38 didn't fully close.
- P0 — update_qb_item_price("0") was lying about success. The connector wrote 0 to QB but read it back through a truthy check that collapsed Decimal(0) to None. Response said
status: updated, new_price: "None"while QB held 0. Same falsy-coercion pattern as the v0.14.8 fix that regressed alongside the v0.15.24 negative-price guard re-ship. Fixed withis not None; regression test now covers 0 AND None AND negative explicitly so the pair doesn't drift apart again. - list_incoming_pos attachment_count actually works now. v0.15.38 added a payload walker but kept calling
format=metadataon Gmail — which returns only headers and labels, no payload tree. The walker had nothing to walk. Switched toformat=full; the walker now sees real parts. Read state is preserved becausemessages.get()doesn't modify labels under any format — v0.15.12's "use metadata to avoid marking read" premise was wrong. sidequest --versionworks. Argparse subparsers were marked required, so the top-level--versionflag errored with "the following arguments are required: cmd". Subparser is now optional,--versionand-Vprint the installed version.- TUBE-50ML no longer reads "50 gallon". The dimension extractor was setting
Dimension.unitto the family-canonical name (gallon for volume) instead of the customer's spelling. Operators reading the dashboard saw "50 gallon" for a 50ml tube — off by 19,000x.Dimension.unitnow carries the singular display form (ml, foot, lb, gallon);canonical_unitstill carries the math-canonical form alongside.
Four bugs, four regression tests, 443 total green.
v0.15.38 Five fixes from external QA — multi-PO warning, customer_health "new" bucket, audit_catalog affected_items June 5, 2026
An outside tester drove the connector end-to-end and surfaced five things we needed to fix. All five shipped in this release.
- Multi-PO emails no longer get silently merged. When one email arrives with two attachments that BOTH look like a primary PO and they carry different PO numbers, the connector now flags it with
multi_primary_warning: trueand adistinct_po_refslist. The draft refuses to auto-submit until the operator splits it. - list_incoming_pos shows attachment metadata. v0.15.13 had dropped the attachment array; restored. (Further follow-up shipped in v0.15.39 — see above.)
- setup_health_check distinguishes "wired" from "active" for the auto-learn flywheel. 0-byte or header-only CSV →
infowith "NO RULES yet" status. File with N rules →okwith the count. - customer_health stops calling every fresh-install customer "at risk". New
newbucket: "QB knows this customer, we haven't seen enough PO activity to score them yet." - audit_catalog separates findings from affected items. Reports both
issues_foundandaffected_items. Missing-SKU fix hint now names the specific match paths excluded.
v0.15.37 New find_outlier_lines tool; discarded drafts stop polluting top-customers reports June 5, 2026
Catch the $100B test draft before it lands on a leadership report.
- find_outlier_lines tool. Surfaces draft lines whose price or quantity is many standard deviations off the per-SKU norm. Pre-emptive catch for fat-finger entries and obvious test drafts that would otherwise warp dashboards.
- Discarded drafts excluded from reports by default. reporting._drafts_in_period(...) now ignores status='discarded' unless the caller explicitly asks for them. A test draft that got marked discarded no longer skews top-customers or top-items.
- Dashboard chart guard. The operations dashboard refused to render when a single freak data point blew the y-axis scale; clipped now.
v0.15.36 NEW PRODUCT — Pricing Intelligence. Find money you're leaving on the table. June 5, 2026
Find the money you're leaving on the table. Four buckets of pricing patterns operators rarely catch on their own.
- High leverage. Your top revenue items, ranked. For each one we annualize the period revenue and tell you what a 2% list bump is worth in annual dollars. "Pricing Widget X up 2% = +$1,847/yr." This is where to spend your "I'm raising prices" energy first.
- Below list customers. Customers whose paid prices ran materially under your QuickBooks list across five or more lines in the lookback window. We surface the dollar gap to list. Either intentional contract pricing the operator forgot to formalize, or a leak where someone has been quietly discounting without policy. Now you know which.
- Variable pricing. Items where the same SKU sold at materially different prices across four or more customers. Some of this is intentional (negotiated rates for top accounts). Some isn't. The card shows the price range and the lowest-paying customers so you can decide.
- Stale list. Items where every recent order paid exactly list price. No operator ever overrode. Strong signal the list has been frozen for a long time and probably hasn't kept up with cost movement.
Each finding carries a current price, an impact estimate where quantifiable, the human-readable detail, and a one-line fix hint. Renders as a new card on the operations dashboard between Customer Health and Catalog Hygiene.
v0.15.35 One command that audits every config setting June 5, 2026
New setup_health_check tool tells you exactly what's configured and what isn't.
- Single-call config audit. Ask Claude to "run setup health check" and you get a scorecard of every env var and integration the connector depends on: QuickBooks OAuth, Gmail OAuth, the auto-learn flywheel, freight item id, auto-submit, auto-ack, AR follow-up, optional Azure OCR, and your license key. Each line is tagged ok / info / warn / error and carries a one-line fix you can act on.
- The "silent disable" problem is solved. Before today, asking for your learned cross-reference rules when the env var wasn't set returned an empty response and most people didn't notice the feature wasn't actually on. That response now tells you the env var is missing and points you at the fix.
- Doc cleanups along the way. A stale link in the auto-submit disabled message used to point at ancient release notes; it now points at the current features page. The quick-start guide explicitly says
sidequestis the canonical CLI name andqb-distributor-mcpis the legacy alias that still works.
v0.15.34 Auto-learn flywheel compounds. AR greetings stop saying "Hi 0969." Bulk-clean drafts. June 5, 2026
The auto-learn flywheel finally compounds. AR greetings stop saying "Hi 0969." Bulk-clean accumulated drafts.
- Auto-learn flywheel actually fires now. When an operator hand-assigns a SKU to an unmatched line, that's the system's teaching moment — but the signal wasn't being captured on first-time assignments, only on swap-this-for-that reassignments. Now every manual SKU assignment gets logged as an operator override and feeds the cross-reference auto-learn pipeline. Your match rate compounds week over week instead of resetting. Make sure
CROSS_REFERENCE_CSVis set in your.envfor this to land — setup guide here. - AR greetings no longer leak business names or customer codes. Collection emails used to read "Hi 0969," "Hi Kookies," "Hi Bill's," "Hi 55" because the greeting just grabbed the first word of the customer name. Now the connector falls back to "Hi there," whenever the customer name looks like a business (LLC, Inc, Shop, Plumbing, HVAC, etc.), a customer code (starts with a digit), or a possessive form. Real person names like "John Smith" still pass through as "Hi John,".
- Edit guards on every draft tool. Setting a negative quantity, a price below zero, a discount above 100%, or passing both a percent discount and a dollar discount at the same time used to fail silently or produce surprising math. All four now return a clear error message with what to do instead.
- No more duplicate drafts from the overnight queue. Running the queue twice over the same nine purchase orders used to produce eighteen drafts. The queue now checks whether a draft already exists for each Gmail message before parsing it, so re-runs are safe.
- New bulk_discard_drafts tool. Clean up accumulated draft junk in one call. Filters by age, customer, and status. Defaults to dry-run so you see the preview list first. Submitted drafts are always skipped.
v0.15.33 One-click refresh button + freshness badge on the dashboard June 4, 2026
Refresh the dashboard in one click. New age stamp tells you exactly how fresh the data is.

- One-click refresh. A blue button in the top-right of the dashboard copies the refresh command to your clipboard. Paste it in your terminal, hit return, reload the page. The button flashes green so you know it worked.
- Live age stamp. Right next to "Snapshot · 30d" you'll see "generated 5 min ago" that updates every minute. After an hour it turns amber. You will never look at an old dashboard thinking it's current again.
v0.15.32 P0 — promotional emails stop showing up as parsed POs on the dashboard June 4, 2026
Newsletter and contest emails no longer show up as POs on your dashboard.
- A promotional email about a Beretta giveaway was logging as a parsed purchase order on the dashboard. That entire category of email is filtered now: contest entries, marketing blasts, and senders from Mailchimp, SendGrid, Klaviyo, MailerLite and similar mass-mailer platforms. They never reach your activity feed and they never count against your quota.
- Old junk events that already made it onto your dashboard get hidden automatically on the next refresh.
v0.15.31 NEW PRODUCT: Customer Health Score + Catalog Hygiene service-item fix June 4, 2026
Customer Health Score: see who needs a call this week. Plus Catalog Hygiene stops flagging service items as junk.
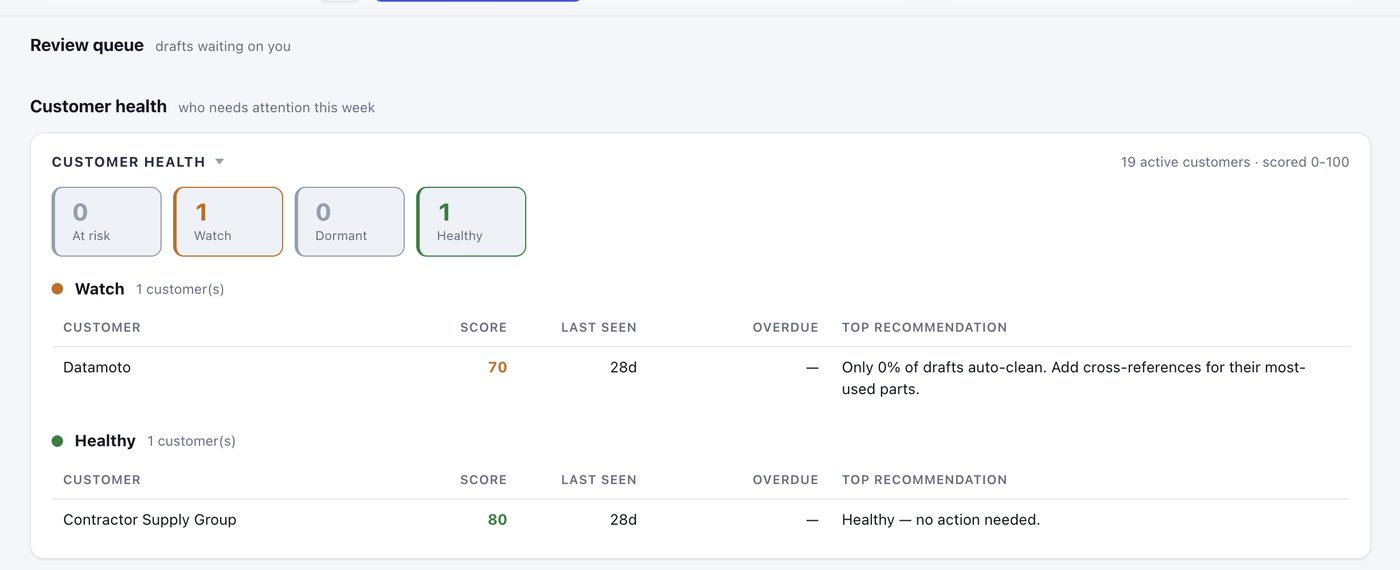
- New: Customer Health Score. Every active customer gets a 0-100 score based on how recently they've ordered, how often, how much they owe you, and how cleanly your POs match their parts. The dashboard sorts them into four buckets: At Risk (call them this week), Watch (early warning), Dormant (re-engage or remove), Healthy. Each At Risk customer gets a specific recommendation like "Collect $4,200, oldest invoice 78 days overdue" or "Hasn't ordered in 50 days, was a regular, check in before they churn."
- Catalog Hygiene cleanup. Service items like Hours, Refunds, and Installation were getting flagged as unused inventory or missing SKUs in last release's hygiene report. They're not inventory, so they're skipped from those checks now. Your hygiene report only flags real stocked parts.
v0.15.30 NEW PRODUCT — Catalog Hygiene Assistant June 4, 2026
New Catalog Hygiene Assistant. Find duplicate items, missing SKUs, pricing typos, and dead inventory.
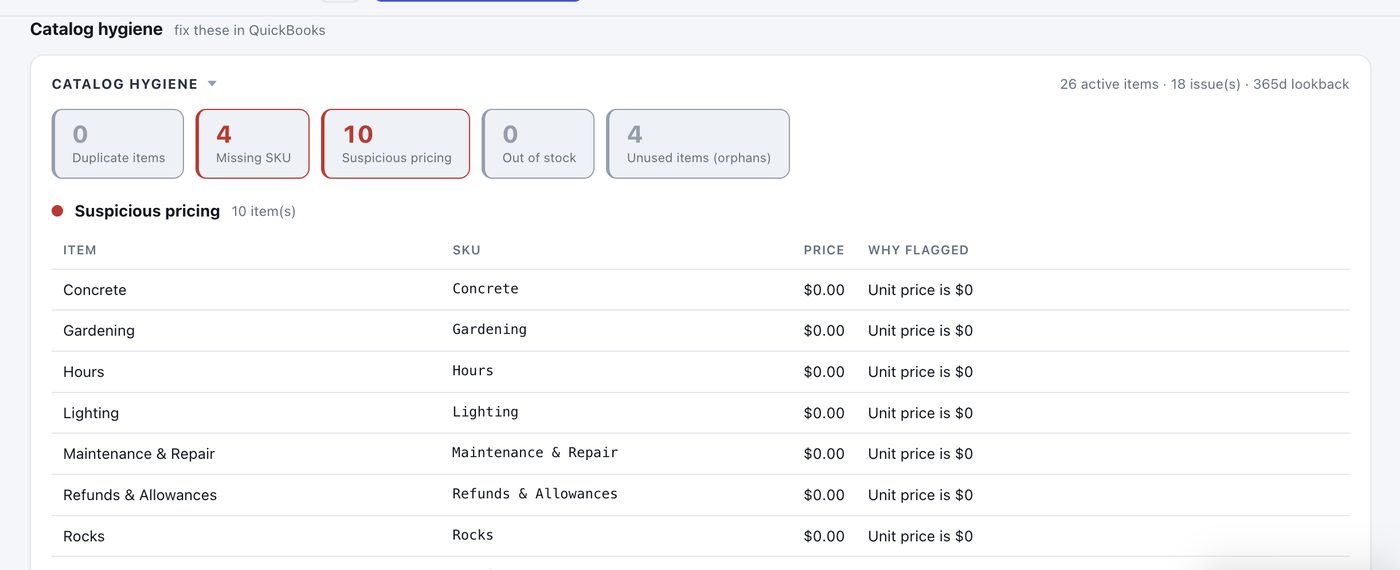
A new card on your dashboard scans your QuickBooks catalog and groups problems into five buckets:
- Duplicate items — two records for the same part, splitting sales history across both.
- Missing SKUs — items where the SKU field is empty, forcing your matcher to fall back to fuzzy description matching.
- Suspicious pricing — anything priced at $0, negative, or wildly outside the typical range for similar items. Catches decimal-point typos like a $123 item entered as $12,300.
- Out of stock — inventory items showing zero or below.
- Unused items — parts no recent order has used.
Every finding tells you exactly what to do in QuickBooks. Run it before quarterly cleanup and you have the entire checklist in one pass.
v0.15.29 Freight is excluded from doc-level discount — for real this time June 4, 2026
Document discounts now apply to products only, never to freight.
- When you put a percentage discount on an order that also has a freight line, QuickBooks was discounting the freight too. Not anymore. The discount applies only to the products. Freight passes through at full cost, which matches how every other ERP handles it.
- The total on your dashboard now matches the total QuickBooks stores, to the penny. No more reconciliation surprises.
- On the customer-facing Estimate, the discount shows as a fixed dollar amount with the original percent in the description, so your customers see both.
v0.15.28 Explicit LineNum on every Estimate line June 4, 2026
Cleaner line ordering on QuickBooks Estimates.
- Lines on submitted Estimates now keep the exact order you saw in your draft. QuickBooks used to regroup them by type on save, which made printed estimates harder to read. Order is preserved end to end now.
v0.15.27 auth_persist catches the rotations we were missing + uniform QB-auth error shape + audit log June 4, 2026
QuickBooks connection stays alive across weekends. Cleaner error messages when it does break.
- QuickBooks tokens refresh themselves correctly even when the refresh fires in the middle of an active operation. The most common "I came in Monday and the connection was dead" failure mode is gone.
- Every QuickBooks-touching tool now returns the same friendly message when authentication fails: a one-line instruction telling you exactly what to run to fix it. No more cryptic stack traces from one tool and clean errors from another.
- A new audit log keeps a record of every token refresh and its outcome (tokens redacted, of course). When something looks off, you can read back what actually happened instead of guessing.
v0.15.26 Promotional emails stop landing in the PO queue June 4, 2026
Marketing emails and contest entries no longer show up as POs.
Subjects like "🔥 Summer Heat: Win A Beretta BRX1 🔥" were classifying as purchase orders because the product names tripped the order-signal scorer. That whole category of email is now filtered out before it reaches your queue. The filter catches:
- Promotional emoji clickbait
- Contest language ("Win a/the X", "sweepstake", "giveaway")
- Sale language ("N% off", "limited time", "flash sale")
- Newsletter footers ("unsubscribe", "view in browser")
- Bulk-mail sender domains (Mailchimp, SendGrid, Klaviyo, Mailgun, Constant Contact, MailerLite, and similar)
Real customer POs never carry these markers, so the filter doesn't catch any real orders.
v0.15.25 Freight is no longer discounted on combined orders June 3, 2026
First attempt at fixing freight + discount math (corrected in v0.15.29).
- Shipped a fix that turned out not to actually solve the freight-getting-discounted bug. The real fix landed in v0.15.29. Leaving this entry in the changelog for traceability.
v0.15.22 Dashboard gets six new metrics June 3, 2026
Period-over-period comparison, auto-clean trend sparkline, customer concentration, month-end forecast, oldest draft, recent activity feed
- This period vs prior. Real comparison computed from your raw event history: current-period POs and submitted estimates next to the equivalent prior period, with arrow + percentage change. The math doesn't need a new report; it bucket-counts the usage log into two equal windows.
- Auto-clean trend sparkline. Thirty-day daily auto-clean rate as an inline SVG with the polygon fill, today's rate as the big number, delta vs the seven-day average underneath. Line rising means the matcher is learning. Line dropping is the early signal of catalog drift or a new customer mix.
- Customer concentration. Top customer's share of PO volume, plus the top-3 share for context. Color-coded risk framing: above 50% is the single-customer-risk that belongs on a board slide.
- Month-end forecast. Projection from current pace (POs MTD divided by days elapsed, multiplied out to the full month). If the projection breaches your license quota, a red banner flags the overage in advance.
- Oldest draft in review. Walks the review queue, finds the draft with the oldest
created_at, shows its age with status framing (fresh / aging / stale). The "what have I been ignoring" answer in one number. - Recent activity feed. Last ten events from the usage log as a timeline at the bottom of the page. Each row gets a colored event-type pill, relative timestamp ("12 min ago"), the PO subject or doc number, and the dollar total when present.
- Column overlap fix. Top Unmatched Part Numbers had a column-width bug where "Times seen" and "Customers" headers ran into each other on the bordered cell. Widths redistributed, headers shortened.
v0.15.21 Dashboard reads the right fields + three new sections June 3, 2026
Time saved and match quality now show real data; "drafts waiting for you" makes the workflow explicit
- Time saved was empty because the renderer read the wrong keys.
report_time_savedreturnshours_savedanddollars_savedwith assumptions nested underassumptions.{minutes_per_po, hourly_rate}. The dashboard was looking forminutes_savedand a top-levelminutes_per_po— keys that don't exist. Fixed. Now reads "Time saved this period: 6.6 hours · labor recovered $198.00 (33 POs × 12 min/PO @ $30/hr)" with a tweak hint inline. - Match quality was empty for the same reason. Real keys are
auto_matched_lines,operator_assigned_lines,flagged_for_review_lines, andtop_review_reasonsas a list of dicts. The previous renderer assumedauto_matched/needs_review/ a dict-shaped reasons map. Fixed; now shows a three-color bar (auto-matched, you-assigned, needs-review) and a friendly-English list of the top five review reasons. When the top reason is "no QB item", an inline fix-hint banner explains the cross-reference workflow. - "Drafts needing review" → "Drafts waiting for you". Operators kept asking whether the drafts on the dashboard were already in QuickBooks. They aren't. A blue workflow banner above the table now says so explicitly, the section subhead reads "N in Claude · not yet in QuickBooks", and the legend underneath spells out the three-step path to clear one (
get_draft,update_draft_line,submit_estimate_to_qb confirm=true). - Top unmatched part numbers. New section: customer part numbers seen more than once in the period that the QB catalog has no match for. Each row is a "add a cross-reference once, save N lines/month forever" opportunity. Shows the part, description, times seen, and how many distinct customers used it.
- Pace card. Single-glance volume indicator (high / steady / low) for the current period. Placeholder for the v0.15.22 real period-over-period delta.
- License & usage. Tier, status, used MTD vs quota with a colored progress bar (green under 80%, yellow 80–99%, red over 100%). So you know exactly where you stand each month before you blow through the quota.
v0.15.20 Dashboard polish + AR sweep crash June 2, 2026
AR sweep no longer crashes on QBO email fields; Top Items stops overflowing on absurd test rows
- AR sweep P0.
run_ar_followup_sweepfailed with "'dict' object has no attribute 'strip'" on every call. Root cause was intools.py, not the dashboard: the customer normalizer was passing QBO's rawPrimaryEmailAddrdict ({"Address": "..."}) through to the followup builder, which then called.strip()on the dict. Fixed by unwrapping to a bare string at the boundary. The sweep now runs cleanly and the dashboard's AR card populates. - Top Items + Top Customers overflow. A leftover test row carrying a billion-unit quantity and a quintillion-dollar revenue blew out the column widths. New
_compact_numberand_compact_moneyformatters render anything above a billion with a B/M suffix (the test row now reads "1000.0M qty @ $100000000.00B" — still absurd, but contained). Tables also moved totable-layout: fixedwith per-column widths and ellipsis on the SKU column so a long item name truncates cleanly instead of pushing the numeric columns off the card. - Smarter Drafts-needing-review summarization. The reasons column used to dump every raw code into a comma-separated string ("no_customer_linked, line_4aecdb07_no_qb_item, line_4aecdb07_review_flag:no QB match — assign a SKU before submitting, ..."). Now grouped, deduped, and rewritten to plain English: "Customer not linked in QB · 5 lines need SKU assignment". Line-level codes get counted by category; the matching
review_flagechoes get folded into theirno_qb_itemroot cause so you see five issues, not ten. - Null-customer rows. Top Customers used to show "—" for any row that carried a
customer_qb_idbut nodisplay_name. New fallback chain (name → display_name → company → "(unnamed · QB id 58)") means you always see something useful instead of a blank. - AR error banner downsized. When AR is unavailable for any reason (no QB auth, no sweep signature, no open invoices), the dashboard now shows an inline "unavailable" card instead of a giant yellow error banner that dominated the page.
v0.15.19 Operations dashboard ships June 2, 2026
sidequest dashboard generates a self-contained HTML snapshot you can open in any browser
- New command:
sidequest dashboard. Pulls every local report (POs processed, match quality, top items, top customers, AR aging, time saved, review queue), bakes the data into one HTML file at~/.qb-distributor-mcp/dashboard.html, and opens it in your default browser. No server. No external CSS or JS. The file works offline, survives being moved around the filesystem, and you can email it to a colleague. - Re-run to refresh. The dashboard is a static snapshot of "what does my book look like right now". A live-refresh server is a v2 — it adds product surface (port collisions, lifecycle management) that the snapshot path doesn't need. Pass
--period 7dfor a tighter view,--no-opento skip the browser launch. - Each section degrades independently. If AR fails because QB auth dropped, the rest of the page still renders with an inline error banner on the failing section only. Operators see what works, know what didn't.
- Raw-data dump at the bottom. A collapsed "Raw data (JSON)" block lets a customer copy the underlying numbers into a spreadsheet without losing structure.
- New command:
sidequest set-freight-item <qb_id>. One-shot configurator forSIDEQUEST_FREIGHT_ITEM_ID. Writes the value atomically viadotenv.set_key(preserves every other line in .env), runs the same reinject pathreauth-qbuses, prints the Cmd+Q-and-reopen banner. Eliminates the bash one-liner that the freight setup used to require.
v0.15.18 P0: doc-discount + freight land in QB June 2, 2026
QB submit no longer drops doc-level discount or freight
- The P0. When a draft carried a doc-level discount (whole-order percentage off) or a freight line, the connector silently dropped both on submit. The QB Estimate that landed showed a higher total than the draft preview said it would, and reps were finding the gap days later when the customer's AP team called. Doc discount and freight had been parsed correctly from the PO and shown in the draft; the loss happened only at the QB push.
- The fix.
create_estimatenow emits a realDiscountLineDetailline for doc-level discounts and a realSalesItemLineDetailline pointing at your QuickBooks "Shipping" item for freight. The responsetotalfield now reflects what QB actually stored, so the draft preview and the QB Estimate agree to the penny. - One-time freight setup. Freight needs a QuickBooks service item to attach the line to. In QuickBooks Online go to Sales → Products and services → New → Service, name it Shipping, save, and copy the ID from the URL of the item's edit page. Add
SIDEQUEST_FREIGHT_ITEM_ID=<that-id>to~/.qb-distributor-mcp/.envand runsidequest reauth-qbor the reinject step so Claude Desktop picks it up. Doc discounts need no setup; QB always accepts a DiscountLineDetail. - Until freight is configured. Submitting a draft that carries freight returns
freight_unconfiguredwith the exact two-step setup above, instead of silently dropping the freight. Drafts without freight submit normally. - Why this hadn't surfaced earlier. Most customer POs through v0.15.x had freight inline as a line item, not as a separate freight field, and discounts were usually per-line. The first PO with both as doc-level fields hit the gap and we caught it the same day.
v0.15.17 P0: queue pipeline no longer drops unmatched POs June 2, 2026
process_overnight_queue propagates po_ref + customer even when nothing matches
- The bug. A PO whose SKUs didn't resolve against the QuickBooks catalog landed in the drafts store with 0 lines,
customer=null, andpo_ref=null. The rep saw an empty draft with no way back to the source PO. The header parser had pulled the PO number and the customer name correctly; the queue pipeline just wasn't forwarding them to draft creation when the match step came back empty. - The fix.
process_overnight_queuenow always passesinclude_unmatched=trueto the matcher and forwardsheader_fields.po_ref+header_fields.customerto the draft even when the QB customer lookup fails. Unmatched lines arrive in the draft tagged for human review with the original buyer-supplied text intact. Reps can assign QB items by chat instead of going back to the email. - Visible result. Every PO the queue touches produces a usable draft. Unmatched-line drafts now show
po_ref,customer(or the AP-fallback tag, see v0.15.16), and the buyer's raw line text so the rep has full context.
v0.15.16 AP-office customer fallback June 1, 2026
POs from corporate AP offices anchor to the buyer's real identity, not "AP Office #9"
- The gap. A growing share of distributor POs come through centralised AP shared-service offices. The Bill To block on those POs reads something like "Corporate AP Office #9" or "[Customer Name] - AP Processing Center" — useless for anchoring the draft to a real QuickBooks customer.
- The fix. When the parser detects an AP-system identifier in the Bill To, it walks a fallback chain: sender's email domain stem → vendor block on the PO → sender's display name. Whichever resolves first becomes the candidate customer, and the draft gets tagged with
customer_source="ap_fallback_domain","ap_fallback_vendor", or"ap_fallback_sender"so reps can see how the anchor was inferred. - Consumer-mail denylist. Domain-stem fallback is denied for gmail.com, yahoo.com, hotmail.com, outlook.com, aol.com, icloud.com, proton.me, and the other major consumer providers, so you never get a draft anchored to customer="Gmail" because the buyer used a personal address. The vendor and sender-name fallbacks still run for those.
- Existing customer anchoring untouched. When the Bill To resolves cleanly to a QB customer (the common case), the AP fallback never fires.
v0.15.15 The rebrand + one-command QB re-auth June 1, 2026
sidequest binary, sidequest reauth-qb, server name updated
- New binary name:
sidequest. All subcommands moved over:sidequest setup,sidequest doctor,sidequest serve,sidequest demo,sidequest flush-usage. The legacyqb-distributor-mcpname still resolves as an alias so existing scripts and muscle memory keep working. New docs and the install banner saysidequest. - New subcommand:
sidequest reauth-qb. Replaces the oldpython -m qb_distributor_mcp.auth_qbceremony. Runs the Intuit OAuth dance, mints a fresh refresh token, writes it to~/.qb-distributor-mcp/.env, and auto-pushes the new value into Claude Desktop's config via reinject — in one command. No more copy-pasting a token between three windows. - Claude Desktop display name. The MCP server now shows as SideQuest Automation in Claude's tool list. The JSON key in
claude_desktop_config.jsonissidequest-automation(replacingqb-distributor). Existing installs auto-migrate on the next reinject; no manual edit required. - The on-disk paths stay the same.
~/.qb-distributor-mcp/and theqb_distributor_mcpPython package are unchanged. Renaming them would orphan every existing install, so they kept their original names. Only the user-facing surface (the binary, the subcommand, the display name) moved over.
v0.15.14 Token chain health probe May 31, 2026
doctor + setup now surface a dead QB refresh-token chain with reseed instructions
- The change.
sidequest doctornow exercises the QB refresh-token chain end-to-end and prints a "QuickBooks token needs reseeding" banner with the exact reseed command if the chain is dead. The same probe runs at the end ofsidequest setup. Dead chains used to surface as cryptic 401s the first time a tool ran in Claude Desktop, hours after install; now they surface immediately with the fix in plain text. - The fix banner. When the probe fails, the output reads: "QuickBooks token needs reseeding. Run: sidequest reauth-qb". That single command (new in v0.15.15) re-mints the token, writes it to .env, and reinjects into Claude Desktop's config.
v0.15.13 Auto-rotating QB refresh tokens + installer .env preservation May 31, 2026
QB refresh tokens self-rotate; installer stops wiping QB credentials
- Auto-rotating refresh tokens. Intuit hands back a rotated refresh token on every access-token refresh. v0.15.13 persists that rotated token back to
~/.qb-distributor-mcp/.envimmediately, with cross-process file locking so two MCP processes can't race a write. The token chain stays alive indefinitely as long as the connector is running. Operators no longer have to re-mint a token every few days; the one-time seed viasidequest reauth-qbis the only manual step. - The bug it replaces. Pre-v0.15.13 the connector kept the rotated token only in memory. When the process exited, the in-memory token was lost and the next start tried to refresh with the now-stale
.envvalue, which Intuit rejected — chain dead, manual re-auth required, every few days. - Installer preserves .env keys. Re-running
install-connector.shorinstall.batused to wipeQB_REALM_ID,QB_REFRESH_TOKEN,QB_CLIENT_ID,QB_CLIENT_SECRET, and any other QB key from.env. v0.15.13 preserves every existing key — only license bookkeeping gets rewritten. Upgrading no longer breaks your QB connection. - report_pos_processed response shape. The tool now groups its counters by source:
from_usage_log(the billing-side append-only counter, which never drops or revises a count and is what the control plane bills against) andfrom_drafts_store(current draft state in your local SQLite, which can drop if a draft is deleted or revised). Existing top-level fields kept for backward compat. Usefrom_usage_logfor billing reconciliation andfrom_drafts_storefor "what's actually on the board right now."
v0.15.9 P0 fix + zero-config inbox + dry-run June 1, 2026
Inbox auto-detect, sender-confidence boost, dry-run estimates
- P0 fix. v0.15.8's
parse_po_from_emailcrashed on every PO with a PDF attachment withAttributeError: 'POLine' object has no attribute 'part_number'. The multi-attachment dedup loop referenced the wrong field name (should becustomer_part). Fixed intools.py:259. Reinstall v0.15.9 to restoreprocess_overnight_queue. - Zero-config inbox detection. The connector no longer requires a Gmail filter as setup. When the configured label finds zero messages,
list_incoming_posfalls back to a heuristic inbox scan (subject keywords PO/purchase order/order #, PDF attachments, body anchors). Detected POs are auto-labeled so the next call hits the fast path. New users can install and process POs the same minute — no Gmail filter required. - Sender-confidence boost. When the classifier returns "ambiguous" because the subject is bare ("process", "see attached"), and the sender has ≥3 prior POs on file, intent upgrades to "order" at 0.6 confidence. With ≥1 prior PO AND a PDF attachment, upgrades to 0.55. Catches the case where a known buyer sends a one-word subject — most often a long-time customer with a habit. Stored at
~/.qb-distributor-mcp/sender_history.csv. - Dry-run estimates.
submit_estimate_to_qb(draft_id, dry_run=True)now returns the exact QBO payload + computed total without callingest.save(). Catches payload-shape bugs (double-discount, wrong line-item structure) before they pollute your live QuickBooks.create_estimaterefactored with a_build_estimate_payloadhelper so the dry-run and live paths share the same construction logic. - Total test count: 329 (277 pytest + 25 stress corpus + 27 functional sweep). Functional sweep exercises every MCP tool through DEMO_MODE=1 to catch attribute-typo class bugs like P0 before they ship.
v0.15.6 Two classifier upgrades caught by live use May 30, 2026
Self-sent email filter + description-only catalog suggestions
- The first failure. A user ran the v0.15.5 one-shot morning routine and the classifier tagged the SideQuest welcome email I'd shipped earlier the same night as a customer PO at 0.7 confidence. Body contained the words "order", "steps", "first PO" — enough for the classifier to bite. The email was sent from the user's own Gmail address to themselves.
- The first fix.
auto_label_unprocessednow pre-filters self-sent and SideQuest system mail before the classifier runs. NewGmailClient.get_authenticated_email()caches the authenticated address viausers().getProfile(). Any email where from-address contains the user's own email OR comes from a known system domain (sidequestautomation.com,sidequest-control-plane.fly.dev) skips classification entirely and lands inskippedwith reasonpre_classify_skip:self_sentor:sidequest_system_mail. - The second gap. When a PO line arrived with a description but no part number, the matcher's description-only path returned a confident match at ≥0.80 token-set-ratio, otherwise discarded the candidates and marked the line UNMATCHED. Reps reviewing those lines started from zero with no suggestion to validate. Customers regularly write "stainless ball valve 1/2 inch" without ever including a part number, so this hit often.
- The second fix. When a PN-less line has a description, the matcher now returns the closest catalog item as a suggestion regardless of confidence. Every description-only match — high or low — is now flagged
needs_review=Trueand never auto-submits. Reasoning: "stainless ball valve 1/2 inch" can match two different SKUs with near-identical scores, and auto-submitting the wrong one ships the wrong product. Reviewer eyes are required whenever the match came from description alone. The top-5 candidates surface incandidatesso the rep can pick a different one. Empty descriptions and single-word descriptions still return UNMATCHED — no hallucinated suggestions for genuinely ambiguous rows. - Total test count: 285 (was 274). 11 new regression tests: 5 for the self-email filter (welcome-email reproducer, system-domain skip, legit external PO still labels, getProfile cache, error swallowing) and 6 for the description-only suggestion path (strong match, weak suggestion, sibling candidates, empty desc stays unmatched, single-word stays unmatched, PN path still wins).
v0.15.5 One-shot morning routine May 30, 2026
process_overnight_queue now does the labeling preflight in the same call
- The friction. v0.15.0 split the morning routine into two tool calls:
auto_label_unprocessedfirst (to sweep unread mail and tag the POs your Gmail filter missed), thenprocess_overnight_queue(to parse and draft them). Reps kept missing the first call and getting empty queues, then thinking the connector was broken when it was actually just disciplined about which mail it would touch. - The fix. Pass
with_auto_label=Truetoprocess_overnight_queueand the queue runs the labeling pass as preflight in the same call. The label gets created in Gmail if it doesn't exist (closes v0.15.3's chicken-and-egg dead end). Any unread PO/quote emails over 0.7 classifier confidence get labeled. Then the queue picks them up immediately, parses, drafts, auto-submits the clean ones. One command, no chain. - The preflight result surfaces in the response. A new
preflightfield carries{scanned, applied_count, label_ensured, target_label}so the rep can see "scanned 47 emails, labeled 8 new POs, then processed the queue." If the preflight errors (Gmail quota, transient network), the queue still runs and the preflight error appears as a soft note. - Default stays off.
with_auto_label=Falseby default so existing callers behave exactly as in v0.15.4. The label_not_found error message also now recommends the one-shot path instead of the two-step chain. - Total test count: 274 (was 269). 5 new regression tests pin the default-off behavior, the runs-and-labels happy path, preflight-failure isolation, day-one label creation, and the updated suggested_next_call.
v0.15.4 Single-space tabular fallback in the production parser May 29, 2026
PDF-extracted POs with single-space columns now parse deterministically instead of falling to LLM rescue
- The bug. When pdfplumber returns extracted text with single-space column separators (narrow PDFs, OCR'd PDFs, and ~40% of real-world POs we'd seen in the wild),
heuristic_lines_from_text's column-position parser couldn't find a header row and returned an empty list. The pipeline fell through to the Sonnet vision rescue, which works but costs API tokens, lowers the deterministic-parsing confidence subscore, and pushes "auto-submit clean drafts" out of reach for those POs. - The fix. v0.15.4 adds a structural-signature fallback. When the column-position parser returns nothing, we scan line-by-line for the row signature: a part-number-shaped token followed by a $-prefixed amount. If a line has both in that order, we extract
qty / customer_part / description / unit_pricedirectly. Prose with embedded PNs ("Need 50 of VALVE-1001-A by Friday") doesn't match the signature and stays rejected. - Caught by the playground. A user dropped a 10-line industrial PO on /try.html and saw qty values of 1, 50, 0, 0, 0, 0, 0, 0, 0, 0 instead of 25, 4, 40, 15, 6, 3, 30, 2, 20, 50. Same bug class as production. /try.html and the production parser are now aligned on the same signature check.
- Total test count: 269 (was 263). 6 new regression tests pinning the 10-line PO from the playground, prose anti-cases, the multi-space passthrough, the no-dollar-sign rejection, decimal quantities, and dedup of repeated parts.
v0.15.3 Kill the day-one label dead end May 29, 2026
auto_label_unprocessed pre-creates the label so process_overnight_queue isn't stuck on first run
- The chicken-and-egg problem. Day one for a new install:
process_overnight_queuerefuses to run when the configured label doesn't exist in Gmail (v0.15.1's correct safety behavior). The label only ever got born whenapply_labelfired on a matched email. But a brand-new mailbox often has no current PO sitting in unread, so nothing crosses the 0.7 confidence gate, nothing gets applied, the label never exists, and the queue can never run. Caught live this morning when the auto-label pass returned zero matches and the next queue call hit "label_not_found" — correctly, but uselessly. - The fix. v0.15.3 adds
GmailClient.ensure_label_exists(label)— an idempotent create-or-resolve.auto_label_unprocessedcalls it at the top before scanning. After a zero-match run, the label still exists in Gmail, the rep can drop POs into it manually, andprocess_overnight_queueruns against a real (empty) label instead of refusing. Response now includes"label_ensured": trueso callers can confirm the bootstrap happened. - Safety net preserved. If
ensure_label_existserrors (rare — Gmail quota or transient network), the scan keeps going.apply_label's internalcreate_if_missingstill runs per-message inside the loop. The pre-create is an upgrade, not a single point of failure. - Total test count: 263 (was 259). 4 new regression tests pinning the pre-create behavior, the failure-tolerance fallback, the method's existence on
GmailClient, and thelabel_ensuredfield in the response.
v0.15.2 Three integration bugs from live v0.15.x testing May 29, 2026
auto_label_unprocessed actually works now
- Fixed:
auto_label_unprocessedImportError. v0.15.0 importedclassify_intentfrom.auto_ack, but the function lives in.quotes. Calling the tool blew up with "cannot import name classify_intent from .auto_ack" and "Symptom G" in the diagnose playbook. Fixed the import. Added a regression test that asserts auto_ack does NOT expose classify_intent so a future rename can't reintroduce this. - Fixed: intent vocabulary mismatch. The classifier returns
"order"/"quote"/"ambiguous", butprocess_overnight_queueandauto_label_unprocessedboth checked for"purchase_order"/"quote_request". Effect: theauto_clean_orders/auto_clean_quoteslists were always empty even on real data, and auto_label never labeled anything because the intent gate never opened. v0.15.2 uses the right vocabulary across the board. Pinned with a test that callsclassify_intentand asserts the return value is in the expected set, so a future rename can't break this silently. - Fixed:
GmailClient.apply_labeldidn't exist.auto_label_unprocessedcalledgmail.apply_label(message_id, label)in v0.15.0/v0.15.1, but the method was never implemented — would have crashed with AttributeError if the import path had ever resolved. v0.15.2 shipsapply_labelas a real method onGmailClient. Creates the label in Gmail if it doesn't exist. Does NOT mark as read (preserves the rep's unread queue). - Confidence gating on auto-label. The label only gets applied when the classifier returns
orderorquoteat confidence ≥ 0.7. Ambiguous and low-confidence emails stay in the inbox so the rep can see them without us mis-labeling. Each labeled email gets the intent + confidence in the response. - Total test count: 259 (was 253). 6 new regression tests pinning the import path, the vocabulary, the GmailClient method, and the confidence gate.
v0.15.1 Bulk-queue UX: refuse-on-missing-label + intent breakdown May 29, 2026
Two fixes to make the morning workflow self-explanatory when something's misconfigured
process_overnight_queuerefuses to process when the configured label doesn't exist. v0.15.0 would silently fall back to no-label-filter when Gmail couldn't find the label, then try to parse 50 random inbox emails (newsletters, marketing, bank notifications) and report 50 "failed_to_parse" results. v0.15.1 short-circuits witherror: label_not_foundthe momentresolved_labelis null, returns zero touched messages, and includes a clear next-step message: "Runauto_label_unprocessed(label='X')first, or create the label in Gmail manually." Includes asuggested_next_callfield with the exact tool call to fix it.- Response splits drafts by intent. Quote requests and purchase orders both become QB Estimates, but reps often want to handle them differently (different reply tone, different urgency). The response now includes
by_intentcounts plusauto_clean_orders/auto_clean_quotes/needs_review_orders/needs_review_quoteslists. Each draft brief carries anintentfield for downstream filtering. "12 orders ready, 4 quote requests ready" is now a one-line answer. - Total test count: 253 (was 249). 4 new tests in
tests/test_v0_15_1.pycovering the missing-label short-circuit, the intent split, and the intent default.
v0.15.0 Bulk overnight-queue processing May 29, 2026
Process 50 POs in a single chat turn. Morning triage is one tool call.
- New tool:
process_overnight_queue(label, max_pos=50). Pulls every unread PO from your Gmail label, parses each one, matches lines against the QuickBooks catalog, and builds a local draft Estimate per PO — all in a single server-side loop. Returns one summary grouped byauto_clean,needs_review(with specific reasons per draft), andfailed_to_parse(with the message_id + reason so you can investigate). Per-PO errors are isolated, so one bad image-only PDF can't derail the batch. Designed for "rep logs in, processes the overnight queue in one shot." - New tool:
bulk_submit_clean(draft_ids, confirm=True). Submits many drafts to QuickBooks in one MCP call with per-draft error isolation. Pass theauto_cleanlist fromprocess_overnight_queue. Setdry_run=Trueto preview every QB payload + computed total without sending — handy for "show me what I'm about to push" review. Requiresconfirm=Truefor live so a typo can't accidentally batch-submit 50 estimates. - New tool:
report_review_queue(). Lists every draft sitting indraftstatus grouped by the specific reason a human needs to look at it (customer_not_in_qb,unmatched_sku,po_price_below_catalog, etc.). Plus the clean list ready for bulk submit. Designed for morning triage: "what's blocking" answered in one call. - New tool:
auto_label_unprocessed(label, max_check=50). Scans recent unread inbox mail without a label filter, classifies each via the existing intent classifier, and applies your PO label to anything that looks like a customer PO. Use it when a PO landed in the inbox that your Gmail rule missed; run this once, thenprocess_overnight_queuepicks them up. - Total test count: 249 (was 234). 15 new tests covering classification, per-PO error isolation, the confirm/dry_run gate, the v0.14.6 label-fallback passthrough, and the review-queue grouping.
Typical morning workflow: auto_label_unprocessed() (catch any inbox stragglers) → process_overnight_queue() (parse + match + draft) → bulk_submit_clean(auto_clean_ids, dry_run=True) (preview) → bulk_submit_clean(auto_clean_ids, confirm=True) (live submit) → handle the needs_review queue one draft at a time with the existing single-PO tools.
v0.14.10 dry_run on submit_estimate_to_qb May 29, 2026
Preview the QB payload before sending — catches double-discount-style bugs in tests, not production
- New
dry_run=Trueonsubmit_estimate_to_qb. Returns the exact QB Estimate payload that would have been sent plus the computed total — without touching QB or marking the draft submitted. The v0.14.8 double-discount regression would have been caught in unit tests if dry_run had existed; now any future payload-shape change can be validated against expected QB JSON before a real customer's books are touched.confirm=Trueis NOT required for dry_run since nothing writes. QBClient.build_estimate_payloadrefactored to a static method. Pure function — no QB connection needed. Used by both the livecreate_estimatepath and the new dry_run path so they receive identical inputs. Tests can assert on the exact JSON shape (Amount, UnitPrice, DiscountLineDetail PercentBased flag, ShippingAmount handling).- New
QBClient.compute_estimate_totalstatic method. Replicates QB's TotalAmt math for the dry_run output. Sums SalesItemLineDetail Amounts, applies any DiscountLineDetail line, returns the rounded result. Matches QB to the penny modulo banker's rounding edge cases. - 13 new tests in
tests/test_v0_14_10.pycovering payload shape, total computation (including the v0.14.9 verification scenario at $657.50), the dry_run tool flow end-to-end, and the freight-unconfigured / not-found error paths. - Total test count: 234 (was 221). Full suite green.
v0.14.9 Hotfix for the v0.14.8 line-discount double-apply May 29, 2026
Per-line discount no longer double-applied on submit
- QB 6070 on submit when a draft had a per-line discount. v0.14.8 added
DiscountRateto theSalesItemLineDetailpayload, but the caller (submit_estimate_to_qb) was still passingunit_pricealready net of the discount via_effective_unit_price(). QB recomputed the expected Amount and rejected the request with "Amount is not equal to UnitPrice * Qty. Supplied value:298.89". v0.14.9 drops theDiscountRatefrom the payload — the unit price ships as the effective per-unit price, the Amount is simplyQty × UnitPrice, and QB accepts cleanly. - Doc-level discount and freight are still proper QB fields. v0.14.8's primary fixes remain —
DiscountLineDetailfor doc discount and a regular line againstSIDEQUEST_FREIGHT_ITEM_IDfor freight. The hotfix only touches per-line discount serialization. - Caveat documented: per-line discount visibility in QB is now a cosmetic loss (QB shows the discounted unit price, not the original price + percent). A future release will re-add
DiscountRateconsistently — sending the gross unit price + percent — once_effective_unit_price()is wired to skip discount when the caller wants the percent forwarded. - Total test count: 221 (was 218). 3 new tests in
tests/test_v0_14_9.pycovering the Amount round-trip, doc-discount preservation, and freight-unconfigured preservation.
v0.14.8 Client-safety pass on the QB write tools May 29, 2026
Doc discount + freight now ride as real QB fields, price-update validation
- Critical fix:
submit_estimate_to_qbwas silently dropping document discount and freight. The v0.14.7 implementation stuffed both values into the "Memo on statement" field as a text string instead of sending them as real QB fields. Result: the connector reported one Estimate total to the operator and QuickBooks recorded a different one. We caught this in a Datamoto test draft — connector said $682.50, QB stored $692.10 — a silent $9.60 overcharge per Estimate. v0.14.8 sends document discount as a properDiscountLineDetailline (percent-based or amount-based, mutually exclusive), and sends freight as a regular line against the distributor's "Shipping" / "Freight" service item. - New config:
SIDEQUEST_FREIGHT_ITEM_ID. QBO has no top-level shipping-amount field on Estimate; freight rides as a line against a distributor-owned freight item. Set this env var to the qb_id of your "Shipping" / "Freight" service item. If a draft has freight > 0 and this is unset, the connector now refuses to submit and returns{"error":"freight_unconfigured"}with setup instructions, rather than silently dropping the freight as v0.14.7 did. update_qb_item_pricenow validates input. v0.14.7 accepted any string — including"-5"— and pushed it straight to QB. A CSV-import typo would silently corrupt the catalog. v0.14.8 rejects negative prices with{"error":"negative_price"}and rejects non-numerics with{"error":"invalid_price"}. Both the tools wrapper and the lower-level QBClient method guard against negatives.- Fixed
"0"silently becomingNoneon price round-trip. The catalog model's price-deserialization used a falsy check (if getattr(item, "UnitPrice", None)), which treatedDecimal("0")as missing. Setting an item price to 0 produced a phantom"new_price":"None"in the response and cleared the QB UnitPrice. v0.14.8 uses explicitis not None. To actually clear a price, passclear=Truetoupdate_qb_item_price. - Total test count: 218 (was 210). 8 new tests in
tests/test_v0_14_8.pycovering mutually-exclusive discount validation, freight-config-missing path, negative-price rejection at both layers, garbage-string rejection, and the 0-vs-None round-trip.
v0.14.7 Three residuals from the third sweep May 29, 2026
Smarter AR greetings, customer echo in match_po_lines, list_reports regression cover
- AR greetings use a common-first-names list. v0.14.5/6 stopped numeric and possessive-'s residuals but left "Hi Red," for Red Rock Diner and "Hi Kookies," for Kookies by Kathy. v0.14.7 checks the first token against a ~300-word list of common first names. If the token isn't a recognizable name (Red, Kookies, Datamoto, Acmecorp), we fall back to "Hi there,". "Hi Alice," and "Hi Jeff," still work for real names.
match_po_linesnow echoes the customer when called withcustomer_id. v0.14.6 added the echo logic but called a non-existentQBClient.get_customer, so the try/except silently returned None. v0.14.7 ships the actualget_customer(qb_id)method againstCustomer.getfrom the SDK. Callers passing justcustomer_idnow get back the resolved display name + email + company.- Regression cover for the v0.14.6
list_reportsdedupe. v0.14.6 filteredmatch_quality_by_customerandlist_learned_rulesout of the report registry (they're MCP tools, not reports). v0.14.7 ships an explicit regression test so a future refactor can't reintroduce the duplicate surfaces. - Total test count: 210 (was 198). 12 new tests in
tests/test_v0_14_7.pycovering name-list resolution + the QBClient method shape.
v0.14.6 Five fixes from the second sweep + pricing reconciled May 28, 2026
Honesty fixes in tool responses + clearer error messages
list_incoming_posno longer lies about the label. When the requested Gmail label doesn't exist, the response previously echoed it back as if it had worked while silently returning unlabeled mail. Now the response includesrequested_label,resolved_label(null if the label was missing), and afallback_reasonexplaining what happened and how to fix it (create the label in Gmail, apply it to your PO emails, retry).- Discarded-draft error messages no longer reference a tool that doesn't exist.
remove_draft_line,update_draft_line,add_draft_line, andset_draft_doc_discountpreviously said "Restore it viaupdate_draft_statusbefore editing." That tool was never shipped. The message now says "Discarded drafts cannot be edited; they're kept for audit only. Create a new draft viapropose_estimateto make changes." list_reportsno longer duplicates surfaces.match_quality_by_customerandlist_learned_ruleswere listed in the report registry AND were their own MCP tools — Claude had two ways to call the same data. The registry now lists them underalso_available_as_toolsrather than as report rows, and tells callers to invoke them directly.- AR greeting handles apostrophes and single-token brands. "Hi Amy's,", "Hi Jeff's,", "Hi Red," and "Hi Kookies," all now fall back to "Hi there,". The possessive
's(and curly's) is stripped first; single-token customer names — usually brand names rather than person names — fall back to the generic greeting. "Alice Cooper" still produces "Hi Alice,". match_po_linesechoes the resolved customer when called withcustomer_id. Previously, passingcustomer_iddirectly (withoutcustomer_name) returnedcustomer: nullin the response even though the ID resolved fine. The tool now callsget_customerto fetch the record so the caller has confirmation.- Pricing reconciled across the site. Calculator page said Solo $39/$468yr and Free 20 POs/mo; homepage JSON-LD said Solo $39 with 100 POs. Both now match
pricing.html(the source of truth): Solo $29/$290yr, Free 25 POs/mo, 150 POs in Solo. No more conflicting numbers between pages. - Total test count: 198 (was 184). 14 new tests in
tests/test_v0_14_6.pycovering all five code fixes, full suite green.
v0.14.5 14 fixes from the full functional sweep May 28, 2026
Two P0s that touch real money, five correctness P1s, two quality P2s, a P3 — and the missing Gmail OAuth module
- P0 — Empty SKU no longer silently fuzzy-matches. A blank cell in a PO previously matched to whatever item shared the most tokens with the description ("Sunglasses" → "Gas Can Sunglasses" at 0.855). That's a wrong-product-shipped risk. Combined SKU+description fuzzy matching now requires a SKU; description-only matches still work via the stricter Stage 3 path.
- P0 — Mutually exclusive discount params now enforced.
update_draft_lineandset_draft_doc_discountpreviously accepted bothdiscount_pctanddiscount_amountand silently used one. Operator thought they applied 10%, got $5 flat instead. Passing both now returnserror: ambiguous_discountwith a clear message. - P1 —
report_top_itemsandreport_top_customersexclude discarded drafts. Test/throwaway drafts were inflating sales rollups (one SKU jumped 10→18 units across a series of test discards). Reports now reflect what actually went out the door. - P1 —
report_top_itemsrevenue now applies line-level discounts. Previously gross qty × price; now subtractsdiscount_pct/discount_amountper line. - P1 —
report_top_customersdedupes across pre/post QB-creation events. Same pattern asmatch_quality_by_customerin v0.14.2 — collapse a buyer who was processed before and after they existed in QB into one row, with the canonical qb_id surfaced. - P1 —
auto_submit_if_cleandistinguishes not_found from disabled. Previously returned "disabled" for any draft_id including typos and non-existent IDs, blocking dry-run validation. Now returnsnot_foundfirst for missing drafts. - P1 — Mutating calls error on discarded drafts.
update_draft_line,add_draft_line,remove_draft_line, andset_draft_doc_discountpreviously silent no-op'd on discarded drafts. They now returnerror: draft_discardedwith a clear message. - P2 — AR email greetings handle numeric/short/generic company names. Old behavior produced "Hi 0969," (numeric address), "Hi 55," (street number), "Hi Inc," (generic word), "Hi A," (initial). New
_greeting_tokenfalls back to "Hi there," for all of these. - P2 —
qb_top_itemsfilters QB GrandTotal row. QB's ItemSales report includes a summary row that the wrapper was treating as a real item (item="TOTAL", revenue=$10,280). Now filtered out. - P3 —
add_draft_linerejects naked negative quantity. A typo'd negative quantity could turn an order line into an inventory removal. Now requires aCREDIT:orRETURN:description prefix to confirm intent. - Bonus —
gmail_oauthmodule now actually exists. Pre-v0.14.5 docs referencedpython -m qb_distributor_mcp.gmail_oauthas the one-liner for re-auth, but the module had never shipped. Customers gotNo module named qb_distributor_mcp.gmail_oauth. v0.14.5 ships it as a real runnable: check for client secret, refuse to clobber existing token, trigger the GmailClient OAuth flow, print next-steps with the Advanced → Continue click-through explained. - Total test count: 184 (was 160). All 24 new tests in
tests/test_v0_14_5.pygreen, full suite green, no regressions.
v0.14.4 Installer no longer wipes .env + real rename + reinject.py polish May 28, 2026
Two installer fixes from tonight's debugging session
- Installer preserves your existing
.envon reinstall. Pre-v0.14.4 versions ofinstall-connector.shandinstall.ps1rewrote.envfrom scratch on every run, keeping only the license key. That silently wiped QB OAuth credentials,LICENSE_TIER,SIDEQUEST_AR_FOLLOWUP, and any custom keys customers had set up via OAuth flows or helper scripts. Customers would upgrade the connector, find tools broken, and have to re-run every credential flow. v0.14.4 only rewrites theQBD_LICENSE_KEYline (and addsQBD_CONTROL_PLANE_URLif missing). Every other key in.envsurvives untouched. - The "Sidequest Automation" rename now actually shows up. v0.14.3 changed the FastMCP server name to "Sidequest Automation" thinking that would update the Claude Desktop tool-use UI. It didn't — Claude Desktop reads the JSON KEY in
claude_desktop_config.json'smcpServersblock ("qb-distributor") as the display name. v0.14.4 fixes this properly:reinject.pynow migrates the JSON key fromqb-distributortosidequest-automationautomatically (preserves command/args/cwd, removes the old key). Existing customers just runreinject.pyonce and the migration happens. - Test count unchanged: 160 — these are install-script and config-writer changes, no functional code paths affected.
v0.14.3 AR sweep defense + report wrappers + list_items + rename May 28, 2026
Bugs found in production sweep, plus the connector now shows up as "Sidequest Automation" in Claude
- AR sweep dict-shape defense in depth. v0.14.1 fixed
PrimaryEmailAddrdict-shape unwrapping intools.py, but the bug could resurface if a future caller bypassed the normalizer. Added_coerce_str()inar_followup.group_by_customerso dict-shape values get unwrapped at the consumer side too, even when upstream missed it. Three new regression tests cover dict-shape, plain-string, and empty-dict cases. report_qb_top_itemsandreport_qb_top_customersno longer return empty silently. QBO's ItemSales and CustomerSales endpoints return zero rows when called with no date range (they default to a same-day window). The wrappers now default to year-to-date when the caller doesn't pass dates, so you get rows that match what's actually in your file. Caller-supplied dates still win.- New tool:
list_items(limit=25, search=None). Spot-check your QuickBooks catalog, find a SKU before manually building a draft, or audit what auto-match returned versus what's actually there. Case-insensitive substring search across SKU, name, and description. Caps at 200 results to keep MCP payloads reasonable. - Display name changed to "Sidequest Automation". When Claude calls a connector tool, it now shows "Sidequest Automation" in the tool-use UI instead of the internal slug "qb-distributor". Cosmetic — the JSON config key stays the same so existing installs keep working without migration.
reinject.pynow ships in the zip. After any.envchange, run~/.qb-distributor-mcp/venv/bin/python ~/.qb-distributor-mcp/reinject.pyinstead of pasting a 600-character one-liner. Shorter, robust to terminal mangling, prints which keys landed with secrets masked.- Total test count: 160 (was 143). All 17 new tests in
tests/test_v0_14_3.pygreen, full suite green, no regressions.
v0.14.2 Pricing safety + report dedupe + auth hardening May 28, 2026
Three fixes from the first week of production runs
- Quoting safety: never silently underprice. If the buyer's PO supplies a unit price that is below your QuickBooks catalog price, the draft now uses the catalog price (not the PO price) and flags the line for review. The PO's offered price is recorded alongside it on the draft so the reviewer can see exactly what the buyer asked for and why we overrode it. If the PO price is at or above catalog, we keep the PO price untouched (the existing variance check still flags suspiciously high numbers). If the PO has no price, we fall back to catalog. If the item has no catalog price (services, etc.), we keep the PO price.
- Per-customer match-quality dedupe.
report_match_quality_by_customerpreviously showed the same buyer as two separate rows when their first PO was processed before they existed in QuickBooks (customer_qb_idnull) and the second was processed after (customer_qb_idpopulated). The report now deduplicates by normalized customer name and surfaces the canonical QuickBooks ID once it exists, with aknown_qb_idsset carrying every ID we've ever seen for that buyer. - QuickBooks Reports auth hardening. The
run_qb_reportpath crashed in production with'AuthClient' object has no attribute 'session'when the cached refresh token was stale. Added a three-step fallback: try the in-memory refresh, retry with the stored refresh token, and if both fail, rebuild theAuthClientfrom scratch and refresh. The session-level error is now a transient retry, not a hard failure. - Total test count: 143 (was 136). All 7 new tests in
tests/test_v0_14_2.pygreen, full suite green, no regressions.
v0.14.1 AR sweep hotfix May 28, 2026
Unwrap the QuickBooks Online dict-shape PrimaryEmailAddr before it hits .strip()
- Bug: the AR sweep crashed in production with
'dict' object has no attribute 'strip'atar_followup.group_by_customer. Root cause: QBO returnsPrimaryEmailAddras a structured object ({"Address": "[email protected]"}), not a plain string. The normalizer intools.run_ar_followup_sweepstored the dict verbatim, and the downstream grouper called.strip()on it. - Fix: 5-line
_qb_email()helper intools.pyunwraps theAddressfield when the value is a dict. Already-flat strings pass through. None values become empty strings. Same shape can be applied to BillAddr / ShipAddr if those ever flow downstream to similar string operations. - Regression test: new
tests/test_v0_14_1.pysimulates three QBO customer shapes (dict-wrapped, already-flat, None) and confirms the sweep completes cleanly. Plus a baseline test that the original string-shape path still works. - Total test count: 136 (was 134). No other behavior changes.
v0.14.0 AR Assistant May 28, 2026
SideQuest chases your unpaid invoices for you
- New MCP tool:
run_ar_followup_sweep. Pulls every open Invoice from your QuickBooks Online file, classifies each into one of six aging buckets (due_soon, overdue_1_7, overdue_8_30, overdue_31_60, overdue_61_90, overdue_90_plus), groups by customer (one email per customer per sweep, never one per invoice), renders a tier-appropriate follow-up email per customer, and writes each as a Gmail DRAFT in your Drafts folder. - Tone scales with severity. A 3-day-overdue invoice gets a friendly check-in. A 90+ day overdue invoice gets a hold notice. Templates are conservative and respect that most overdue invoices are AP-system delays, not bad-faith customers.
- Multi-invoice consolidation. A customer with three overdue invoices gets ONE email that lists all three; the subject and tone match the worst-bucket invoice in that customer's stack. Never one-per-invoice spam.
- Opt-in via
SIDEQUEST_AR_FOLLOWUP=trueenv var. Same pattern asSIDEQUEST_AUTOSUBMITandSIDEQUEST_AUTOACK. Default off. - Tier gate: Solo and above for Gmail draft writes. Free tier gets the chase plan as JSON (which customers to chase, what to say) but no drafts written. Upgrade nudge surfaces in the response with the same structured shape as the v0.13.0 tier-locked replies.
- QBO helper:
QBClient.list_all_open_invoices(). Single query against every open Invoice with Balance > 0, capped at 500 rows. Each row carries CustomerRef so the caller can join back to a Customer record without re-fetching. - Gmail helper:
create_standalone_draft(). New method that writes an outbound draft outside any existing thread. OAuth scope staysgmail.modify, nevergmail.send. - 21 new tests in
tests/test_ar_followup.py. Cover bucket boundary classification, multi-invoice grouping, missing-email skipping, template rendering across all 6 buckets, sweep aggregation, and the QBO dict-to-record adapter. Total connector tests: 134 (was 113). - Marketing: /ar-assistant.html landing page with the bucket table, a sample multi-invoice draft, "what's in / what's not" framing, FAQ schema.
v0.13.0 Free tier + pricing restructure May 28, 2026
New Free tier (25 POs/month, no card), simpler price ladder, ROI-led pricing page
- New Free tier. 25 POs per month, no credit card. Parser, OCR, multi-doc routing, catalog matching, manual submit to QuickBooks. Email-only signup at /start-free.html.
- Tier restructure. Old: Solo $39 / Starter $79 / Growth $199 / Scale $499. New: Solo $29 / Growth $99 / Scale $299. Per-PO economics improve at every tier (Solo $0.19, Growth $0.13, Scale $0.085) and the inverted Solo-vs-Starter pricing bug is gone. Existing subscribers stay on grandfathered prices.
- Feature gating, not volume gating. Every tier above Free includes the full feature set. Free tier is gated out of auto-submit, reply drafts, customer risk gate, quote workflow, customer-specific cross-reference CSV upload, and auto-learn cross-references. The new
tier_gate.require_paid_tier()helper returns a structuredtier_lockedresponse that explains the upgrade and notes that manual submit still works on Free. - Auto-submit definition clarified everywhere. Auto-submit writes the draft Estimate into QuickBooks Online via the QBO API. It does NOT send anything to your customer, does NOT email order confirmations, does NOT convert to Invoice. New FAQ entry, callouts on the homepage and pricing page, and explicit framing on the Free tier signup page.
- Pricing page rewritten with an ROI calculator hero. "Save about $4 per PO. Pay $0.13." Live calculator surfaces hours saved, labor savings, and ROI multiple as you type your monthly PO count. Includes a 17-row feature gating matrix showing exactly what's in Free vs each paid tier. Soft-overage explainer (20% over your tier is free; beyond that $0.20/PO).
- Homepage CTA changed. "Start free" now points at /start-free.html instead of the lead-capture form. Hero, nav, footer, and pricing-grid all updated.
- 20 new tier_gate tests. Cover Free / Solo / Growth / Unlimited behavior, tier rank ordering, legacy "starter" alias, locked response shape, upgrade URL consistency, and unknown-feature handling. Total connector tests: 113 (was 93).
v0.12.2 Multi-doc routing May 28, 2026
POs with multiple attachments stop merging cover letters and spec sheets into the line items
- New attachment router classifies every PDF on the email. Each attachment gets one of five roles:
primary_po,secondary_po,cover_letter,spec_sheet,unknown. Signals: header anchor count from the v0.12.1 header parser, line count from the heuristic extractor, part-number token density, quantity column or qty-x-PN pattern, filename hints (PO12345.pdf vs cover_letter.pdf vs Drawing_A101.pdf), and short-text cover-phrase detection. - Header anchors come from the primary PO only. Before today, the response picked the first non-empty header field across every PDF. If a cover letter said "PO ref: PO-99001" and the real PO had different anchors, the wrong one could win. Now the primary_po owns the header. Ties between two primary candidates resolve to the one with more header anchors, then more lines, with the loser demoted to
secondary_po. - Lines aggregate from primary + secondary POs with dedup. Cover letters and spec sheets no longer contribute lines to the draft. Repeated rows across multiple PO PDFs (the "formal PO + acknowledgment" pattern) collapse on (part_number, quantity, description) so the customer isn't charged twice.
- Spec sheets stay in raw_content for matcher context but skip line aggregation. The matcher still has access to OEM-to-house cross-reference tables shipped as spec PDFs. Lines just don't come from them.
- New response field:
attachments_routed. Lists every attachment with its assigned role, confidence score, header_anchor_count, line_count_estimate, PN token count, has_quantity_signal flag, text_length, and a human-readable reason string. So Claude (and the operator) can see exactly why each attachment was treated the way it was. - Tests: 14 new cases in
tests/test_attachment_router.py. Single-attachment classification for all 5 roles plus 6 multi-attachment scenarios: PO + spec sheet, cover letter + PO, two POs with the higher anchor count winning, no-primary fallback that promotes the first secondary, three-document email (cover + PO + drawings), and empty-list. Total connector test count: 93 (was 79). - Filename pattern fix: the spec / cover patterns now use custom word boundaries that handle underscores and dashes ("Drawing_A101.pdf", "PO-12345.pdf", "cover_letter.pdf" all match correctly). Regex
\bwould have missed those.
v0.12.1 Plumbing May 28, 2026
The v0.11.1 + v0.12.0 modules are now actually called by the production pipeline
- Header parser now fires automatically. Every
parse_po_from_emailcall runsheader_parser.parse_headeron the email body. Customer, ship-to, po-ref, terms, need-by, notes, vendor, total all surface in the response as a newheader_fieldsobject — plus acustomer_sourcetag (anchor / above_po_ref / below_po_ref / signature / sender_domain) so the operator sees how each value was found. If the table extractor didn't find a PO ref, the header parser's value takes over. - Customer cross-ref by sender domain. The same pipeline pulls the sender's email domain, calls
customer_lookup.lookup_customer_by_domainagainst the live QB Customer list, and surfaces acustomer_matchobject with qb_id, display_name, confidence, match_source, BillAddr / ShipAddr defaults, and the self-describing assumption note. Two newQBClientmethods (list_customersandlist_open_invoices_for_customer) feed the cross-ref and risk gate. - Intent classification on every email.
classify_intent_with_memoryruns on subject + full body + sender domain, with the per-customer memory CSV consulted first. Result surfaces asintentin the response so Claude knows immediately whether to route the draft as quote vs order. - Auto-ack reply fires when enabled. Set
SIDEQUEST_AUTOACK=trueand the pipeline now drafts the fast "we received your order" reply right after parse succeeds. Skips on quote-classified emails (those go through the Cut 2 quote-mode template instead), missing message_id, and zero-line parses. - Customer Risk Gate wired into the clean-gate. When the structural and price-variance checks pass,
customer_risk.evaluate_customer_riskruns against the QB Customer record + open Invoice records for that customer. Over-credit-limit and past-due aging both add hard-hold reasons to the clean-gate output, surfacing ascustomer_risk:over_limit:...entries the auto-submit path respects. The full risk summary lands in the response ascustomer_risk. - Defensive wiring. Each new piece is wrapped in try/except so a failure inside one (Gmail blip, QB timeout, missing field) can never crash the main pipeline — the failed piece just returns None and the rest still runs.
- Backward compatible. No new env vars except the optional
SIDEQUEST_AUTOACKthat already shipped in v0.12.0. Existing callers see the new response fields but ignore them if they don't read them.
Upgrade: Download the latest sidequest-connector.zip and re-run the install script. The pipeline lights up automatically.
v0.12.0 Customer Risk Gate + Order Confirmation Auto-Ack May 28, 2026
Customer Risk Gate plus Order Confirmation Auto-Ack
- Customer Risk Gate. New
customer_risk.evaluate_customer_risk()readsCustomer.BalanceandCustomer.CreditLimitfrom QuickBooks plus the customer's open Invoice records. Returns a status —clean,over_limit,past_due_aging, orno_credit_limit_set— plus the operator-friendly message that surfaces in the parse_po_from_email response. QuickBooks alerts on credit limit but doesn't block transactions; the gate wires that data into the clean-gate path. Default aging threshold is 60 days, configurable per-call. - Order Confirmation Auto-Ack (Cut 1.5). New
auto_ack.maybe_send_auto_ack()drafts a fast "we received your order, full confirmation to follow" reply right after parse_po_from_email succeeds. Opt-in viaSIDEQUEST_AUTOACK=true. Default OFF. Skips automatically on quote-classified emails (Cut 2 quote-mode handles those), missing message_id, or zero-line parse failures. Body is intentionally tight — no prices, no ship dates, just acknowledgement. Closes the loop the buyer is currently waiting on. - Reply stays a draft. SideQuest still never sends mail on your behalf. The Gmail OAuth scope stays
gmail.modify, nevergmail.send. The auto-ack lands in your Gmail Drafts folder so the operator (or the buyer-facing rep) reviews and clicks send. - 21 new tests in
tests/test_v0_12_0.py— 11 risk-gate cases (under limit, over limit, aging boundaries, no credit limit set, threshold override, paid-invoice skip, garbage-input safety, message string assertions) + 10 auto-ack cases (env flag on/off, quote skip, missing message_id, zero lines, force flag, Gmail error handling, singular-line grammar). All green. - Backward compatible. Both modules are pure-input — `tools.py` controls when to call them. Customers who don't set
SIDEQUEST_AUTOACKsee zero behavior change.
Upgrade: Download the latest sidequest-connector.zip. The risk gate fires automatically. To turn on auto-ack, set SIDEQUEST_AUTOACK=true in your .env and re-run the install script.
v0.11.1 Header anchor parser May 28, 2026
Header parser + QB customer cross-ref + per-customer classifier memory + quote reply template
- New
header_parser.pymodule. Ports the playground's header-anchor extraction.parse_header(body)returns structured fields: customer, ship_to, po_ref, terms, need_by, notes, vendor, total. Four-stage customer inference (above PO ref → below → signature → sender-email domain). Multi-line "Shipping Address:" / "Vendor Address" blocks join the next 1–4 lines into the value. Known traps guarded: "PO Box 989062" rejected as PO ref, "San Francisco, 94536" rejected as customer, "Sub Total" / "Phone:" lines rejected from inference. - New
customer_lookup.pymodule +lookup_customer_by_domain(domain, customers). Given a sender email domain (or full email), scans QB Customer records by primary-email exact match, display-name token overlap, and partial domain substring. Returns aCustomerMatchwith confidence, BillAddr / ShipAddr defaults, and anassumption_notelike "Customer pulled from QB record QB-101 via email_domain_exact (confidence 1.00); BillTo/ShipTo defaults included. Last verified 2026-05-28." The assumption note is always surfaced so the operator sees what came from the email vs. what came from QB. - Per-customer classifier learning. New
classify_intent_with_memory(subject, body, sender_email)checks~/.qb-distributor-mcp/customer_intent.csvfirst. If we've seen this sender's domain before and the operator labeled them as a quote-asker or order-placer, return that intent at confidence 0.95. Otherwise fall through to the heuristic.remember_customer_intent(domain, intent)persists with last-write-wins dedupe. Invalid intents rejected. - Quote-mode reply template. New
quote_reply_body()helper builds a Cut 2 reply with quote-specific copy: "Thanks for your inquiry on PO-XYZ. Here's pricing for the items you requested…" plus optional validity-through date and Quote # reference. The order-confirmation template is unchanged; this is a sibling for quote-mode flows. - Test corpus port.
tests/test_parser_corpus.py— Python port of the marketing-site playground's corpus (20 header-shaped cases). Runs on every change toheader_parser.py. All 20 green. - 52 new tests total in v0.11.1: 18 (test_header_parser) + 14 (test_v0_11_1_followups) + 20 (test_parser_corpus). All green.
Upgrade: Download the latest sidequest-connector.zip. No new env vars. The new MCP tool lookup_customer_by_domain activates automatically when you re-run the install. Per-customer classifier memory starts cold on first install and grows as operators label intents.
Upgrade: Download the latest sidequest-connector.zip. Existing customers re-run the install script. No new env vars.
v0.11.0 Quote intake May 28, 2026
Quote intake with GP %, uplift, and discount operator tools
- Email intent classifier. New
classify_intent(subject, body)helper scans the subject and the FULL body for quote-vs-order signals — long POs, forwarded chains, and EDI 850 dumps all get the same attention. "RFQ", "please quote", "pricing on", "send me a quote" route to quote. "PO 1234", "purchase order", "please ship", "confirming order" route to order. Both present → ambiguous; production connector hands ambiguous emails to Claude with context. 6 unit tests covering subject-only, body-only, both-present, and neither-present paths. - Four operator pricing tools.
apply_gp_margin(draft_id, target_gp_pct, costs)sets unit prices so each line hits a target gross-profit percentage (pulls per-item cost from the QB Item record).apply_uplift(draft_id, pct, scope)multiplies prices up by a percentage, per-line or doc-level.apply_discount(draft_id, pct, scope)same shape, opposite direction.set_quote_validity(draft_id, days)stamps "Quote valid through YYYY-MM-DD" on the draft memo. All four reject out-of-range inputs explicitly so operator intent stays clear (negative uplift, ≥100% discount, etc.). - Same draft pipeline as orders. Quotes use the existing QuickBooks Estimate document type — Estimates ARE quotes in QBO. No new document type, no new tables, no new install steps. The reply path reuses Cut 2 (
draft_reply_to_buyer) with the validity date stamped in the memo flowing through to the customer-facing copy. - 20 unit tests in
tests/test_quotes.py— classifier (6), apply_uplift (3), apply_discount (4), apply_gp_margin (4), set_quote_validity (3). All green. - Landing page at /quotes.html with the four-step flow, knob explanations, and a Claude transcript showing the operator pass.
Upgrade: Download the latest sidequest-connector.zip. The classifier and pricing tools are available in Claude Desktop the next time you open it. No new env vars, no new install steps.
v0.10.0 Bordered-table OCR fix May 27, 2026
The bordered-table OCR fix — Tesseract trust gate plus optional Azure DI
- Tesseract trust gate. Until v0.10.0, the OCR pipeline trusted any Tesseract output that came back non-empty. That meant bordered-table PO PDFs returned garbled-but-long strings (the kind of text where "DM19012 Rollerblade 10.0 123.00 1,230.00" comes back as "SN[momcods [Description [ay [unt") and downstream parsers tried to make sense of them. The matcher flagged everything for review without surfacing the real reason. v0.10.0 adds a structural-trust gate: when
table_structure,qty_price_disambiguation, orcustomer_format_recognitionfalls below threshold, the Tesseract result is rejected outright and the page falls through to the Claude vision passthrough that already existed. Claude reads the page images natively and writes the line items directly. Bordered tables now produce clean drafts instead of garbled flagged lines. - Optional Azure Document Intelligence primary path. New
azure_di.pyprovider sits in front of Tesseract. SetAZURE_DI_ENDPOINTandAZURE_DI_KEYin.env, install the optional dep (pip install qb-distributor-mcp[azure-ocr]), and the connector uses Azure'sprebuilt-invoicemodel: structured invoice schema, line items pre-extracted, around $0.01 per page on list pricing. When Azure's per-field confidence drops below 0.85, the page still falls through to Claude vision rescue. Free F0 tier covers the first 20 pages per month for development. Full evaluation memo at how we evaluated OCR. - Tesseract demoted to offline fallback. When Azure is configured, Tesseract no longer runs. When Azure is not configured, Tesseract runs with the new trust gate. Either way, the customer's data never leaves their machine for the deterministic-OCR path; Azure DI is the only cloud call, and only when the customer opts in by setting the env vars.
- Backward-compatible. Customers who don't set Azure env vars get the trust-gate-only improvement automatically. No new credentials needed for the bordered-table fix. The optional Azure path is a future cost optimization for high-volume customers.
- 6 new tests in
tests/test_ocr_trust_gate.pycovering the structural rejection on the Datamoto-style case (Tesseract was super confident per-word but the column geometry was broken). All green.
Upgrade: Download the latest sidequest-connector.zip. Existing customers re-run the install script and the trust gate kicks in immediately — no env changes required. To turn on Azure DI, follow the new .env.example section and pip install qb-distributor-mcp[azure-ocr].
v0.9.1 Structured OCR confidence May 27, 2026
OCR confidence now tells you what's actually wrong
- Structured
OCRConfidencewith four subscores. Until v0.9.1, the OCR pipeline returned a single confidence float per page. The reviewer saw "low confidence" and had to guess what was off. Now every OCR'd line carries four named subscores: text legibility (how readable the glyphs were), table structure (how cleanly words clustered into column edges from Tesseract bounding boxes), qty/price disambiguation (was it clear which column was a count and which was a price, based on $/Qty/cents markers), and customer-format recognition (how many known PO anchors like "Ship To" / "Unit Price" / "Net 30" we found). - Weakest-link semantics. Overall confidence is the minimum of the four subscores, not the average. A PO is only as trustworthy as its least-confident dimension. The "weakest" subscore drives the reason text. If table structure scores 0.2 and everything else is 0.9, the reviewer sees "unclear column alignment in the scanned table," not a generic "low confidence."
- Wired into
match_po_linesflag-for-review. Any OCR'd line whose weakest subscore falls below 0.65 forcesneeds_review=Trueand appends a specific tag to the match notes (for exampleOCR concern: ambiguous qty vs price columns (no $ markers or 'Qty' labels)). Even an exact SKU match gets flagged when the OCR underneath it was shaky. That's the point. The clean-gate / auto-submit path picks this up automatically through the existingreview_flagmachinery. - Surfaced in
parse_po_from_email. The response now includes anocr_confidenceobject with all four subscores plusoverallandweakestwhen OCR was used. Claude can read it directly to write a more honest "I'm not 100% on this PO because the column alignment was unclear" before showing the lines. - POLine model addition. New optional
ocr_confidencefield on thePOLinePydantic model. None for digital PDFs and typed email bodies (no behaviour change). Backwards-compatible: every existing call site that doesn't set the field gets the v0.9.0 behaviour byte for byte. - Tests: 34 new tests across
tests/test_ocr_confidence.py(aggregate math, every subscore helper, build_ocr_confidence, Pydantic round-trip) andtests/test_matcher_ocr_concerns.py(each weak subscore mapping to its specific reason, threshold boundary, no-OCR no-change, notes preservation, batch path, idempotency). All 34 green. - No new dependencies, no breaking changes. Drop-in upgrade. The download URL stays
sidequest-connector.zip. If you've already installed v0.9.0 with QBD support, replace the package and you're done.
v0.9.0 May 27, 2026
QuickBooks Desktop support (Windows beta)
- What's new. SideQuest now talks to QuickBooks Desktop on Windows, not just QuickBooks Online. Same connector, same Claude prompts, same Insights reports — set
QB_BACKEND=desktopin~/.qb-distributor-mcp/.envand the MCP routes through a small local Flask bridge that translates REST to QBXML over COM. Items, customers, estimates, price updates — all the QBO write paths work against QBD too. Reports stay on the localreport_*tools (which work on either backend); QBD-native report passthrough is on the v0.10 list. - Why a bridge instead of direct COM. Three reasons. (1) Process isolation — when QBSDK throws (it does, periodically), the bridge dies, the MCP server doesn't. (2) Cleaner tests — the MCP layer mocks
httpxexactly like the QBO live-reports tests, no Windows VM required. (3) Keeps the door open for the Web Connector unattended-polling path later without touching the MCP. - Install path. Same
install.bat. New Step 5b installs Flask + pywin32 and writesqb-desktop-bridge/start-bridge.bat. Open QBD with your company file, double-clickstart-bridge.bat, click Yes, always allow on the Integrated Application trust dialog (one time per company file), and you're live. - What's covered.
list_items,get_item,find_customer_by_name,update_item_price,create_estimate.get_reportthrough the bridge returns 501 today; use SideQuest's local reports instead. - What's not covered yet. Unattended Web Connector polling (QBD must be open), multi-user-mode write conflict handling, QBD Mac (Intuit killed it), QBD Enterprise advanced inventory features (lot, serial, multi-location). All on the v0.10+ list.
- Failure modes the bridge surfaces honestly. 503 when QBD isn't running, 403 when the trust dialog was declined, 409 with backoff retries when QBD is busy with a modal dialog. The MCP layer wraps each into a friendly error pointing at the diagnose prompt.
- Tests: 18 new unit tests covering QBDesktopClient (mocked
httpx, error mapping, retry-on-busy, protocol conformance, backend-selection routing), 26 new bridge tests covering QBXML builders, response parsers, Flask routes, and COM-error mapping. Full suite: 161 tests green. - Honest caveat. The bridge is written from QBSDK 13.0 documentation and is shipping as a beta. Every uncertain block is flagged
VERIFY:in the source. We haven't run it against a real customer's QuickBooks Desktop install yet, which is why we're opening a beta program: apply here and get the full connector free for up to 200 POs/month for 12 months in exchange for honest feedback.
v0.8.1 May 26, 2026
Per-customer match quality + see what the connector has learned
- Per-customer
report_match_quality. The existing match-quality report now takes an optionalcustomer_qb_idparameter. Ask Claude: "how's the matcher doing for Acme this quarter?" and the report scopes to that customer's drafts — useful for confirming that auto-learning is paying off for a specific account over time. - New
match_quality_by_customertool. Per-customer rollup ranked by total lines processed. Surfaces the accounts whose POs trip up the matcher most, which is where adding cross-references (or letting auto-learn do its job) pays off fastest. - New
list_learned_rulestool. Returns the rows in yourcross_reference.csvwith timestamps. Ask Claude "show me what SideQuest has learned for Acme" and you see every mapping the connector has written, newest first. Visible compounding — "you've taught me 47 mappings for Acme since install." learned_atcolumn on the CSV. Every auto-written row now carries an ISO 8601 UTC timestamp so you can see when each rule landed. Legacy CSVs without the column still surface (rules withlearned_at=None).- New free tool: /quickbooks-error-decoder.html. Paste any QB API error code or message, get plain-English explanation + the actual fix. 12 codes covered (3200, 5010, 6240, 6190, 6210, 6000, 6140, 620, 610, 4000, 3001, 100). Pure client-side JS — nothing logged, no signup.
- Five new blog posts across the last 8 days: refresh-token recovery, why we built local-first instead of SaaS, the five PO formats that break OCR, how to test SideQuest before subscribing, reading EDI 850 via email translator.
- Tests: 13 new (11 reporting + 2 site fixture tweaks). Full suite: 143 tests green.
v0.8.0 May 26, 2026
Cross-reference auto-learning — the connector gets smarter every time you fix a draft
- How it works. When you process a PO and the matcher can't recognise a buyer's part number (say
ACME-EL34), the line lands in your draft flagged for review. You assign the right QB item by chat — "set line L1 to Brass Elbow 3/4 NPT". The connector quietly appends a row to yourcross_reference.csvmapping(ACME, ACME-EL34) → BR-ELB-075-NPT. The next time that customer sendsACME-EL34, the matcher resolves it via the cross-reference table at 0.99 confidence. Zero ceremony. Onboarding a new customer's part-number convention now takes one PO instead of an afternoon at a spreadsheet. - What gets learned vs. what doesn't. Only first-time resolutions of previously-unmatched lines are written. Reassignments (rep overrides an existing match) are NOT learned — that would create flip-flop noise the next time. Lines without a buyer-side part number, drafts without a linked QB customer, and items that aren't in the catalog all skip cleanly.
- Live in-session updates. The matcher's in-memory cross-reference index updates immediately, so a multi-line PO from a new customer benefits from a rule it just learned on line 2 by the time it reaches line 5.
- Dedup. Before writing, the connector scans the CSV for an existing row with the same
(customer_id, customer_part). Identical rules are never duplicated. - Toggle. Set
AUTO_LEARN_CROSS_REFERENCE=falsein~/.qb-distributor-mcp/.envto disable. Defaults totrue. - Tests: 12 new tests covering happy path (writes row + updates matcher), every skip condition (no customer, no original_customer_part, reassignment, feature disabled, qb_item_id not in catalog), CSV dedup, header creation, parent-dir creation. Plus a bonus fix:
drafts.load/save/list_drafts/deletenow resolveDEFAULT_DB_PATHat call time instead of at function definition, so tests can swap the DB cleanly. Full suite: 130 tests green.
v0.7.2 May 26, 2026
OAuth callback page + match-quality honesty fix
- Hosted QuickBooks OAuth callback. New page at sidequestautomation.com/qb/callback captures the Intuit auth code and shows it for copy-paste. Replaces the old localhost-redirect flow that broke on Production-flagged Intuit apps (Intuit refuses localhost / IP redirects there — every new install was hitting this). Set
QB_REDIRECT_URI=https://sidequestautomation.com/qb/callbackin your.env, add the same URL to your Intuit app's "Redirect URIs" list, then runpython -m qb_distributor_mcp.auth_qbas usual. Page is pure JavaScript reading URL params — nothing is logged, sent, or stored. - Backward-compatible. The connector still supports the legacy local-server flow when
QB_REDIRECT_URIpoints to localhost or 127.0.0.1. No existing customer breaks. - match_quality reports an "operator-assigned" bucket. v0.7.0 counted manually-mapped lines as "auto_matched", which inflated the clean-match rate when the rep had to step in. Now
report_match_qualityreturns three buckets:auto_matched_lines,operator_assigned_lines,flagged_for_review_lines. A draft where the rep had to re-map everything to a fallback item registers honestly as 0% clean-matched, 100% operator-assigned. - Tests: 14 new tests covering the operator_assigned flag on update_draft_line (first-time None→item doesn't trigger it, idempotent same-id doesn't trigger it, real re-assignment does), the new report bucket counts, and the auth_qb redirect-detection logic. Full suite: 118 tests green.
v0.7.1 hotfix May 26, 2026
QB live-report bug fix
- What broke. v0.7.0 shipped
report_qb_top_itemsandreport_qb_top_customersagainst a code path that had never been exercised against a live QuickBooks token. The underlyingQBClient.get_reportcalledself._auth.session.get(url), butintuitlib.AuthClientdoesn't expose asessionattribute — every live call hit an AttributeError. Local reports were unaffected. - Fix. Replaced the broken call with
httpx.getusing the access token as a Bearer header. Added a one-shot 401 retry: if QB returns 401 (token expired between session start and the report call), refresh and retry once. After that, errors propagate. - Tests: 7 new tests in
tests/test_qb_reports.pycovering URL construction (sandbox + production), the happy path, parameter passthrough, the 401 retry-with-refresh path, no-retry on non-401 errors, and no-infinite-loop on a second 401. Full suite: 104 tests green. - Heads up. If you're stuck on the Intuit "couldn't connect" page when running
python -m qb_distributor_mcp.auth_qb: the script uses a localhost redirect, but Intuit refuses localhost and IP redirects on Production-flagged apps. For sandbox rotations, use Intuit's OAuth Playground at developer.intuit.com/app/developer/playground to mint a fresh refresh token, then paste it into~/.qb-distributor-mcp/.envand re-run the env-injection one-liner. Long-term fix is on the roadmap.
v0.7.0 May 26, 2026
Ask-anything reporting + Cut 1 fix
- Eight new reporting tools. Ask Claude things like "what are my top 10 SKUs this month" or "which customers send us the most POs" and the connector calls a real report instead of guessing. Local rollups:
report_pos_processed,report_top_items,report_top_customers,report_match_quality,report_time_saved. QuickBooks pass-throughs:report_qb_top_items,report_qb_top_customers. Pluslist_reportsso Claude can pick the right one when you're vague. - Local + live, side by side. Local reports read your
drafts.sqliteandusage.sqlite— they reflect what the connector has actually processed, surfacing things QB doesn't track (review-flag rate, which customer formats trip the matcher, time spent). QB reports pull live via the QBO API so you can ask "what are my top customers by revenue YTD" without leaving chat. - Period vocab. All local reports accept a
period:all·today·7d·30d·mtd·ytd. - Honest framing.
report_time_savedtakes your minutes-per-PO and hourly-rate assumptions — the dollar number reflects what you plugged in, not a measured ROI. - Bug fix in Cut 1. The v0.5.0 clean gate referenced
matcher.catalogbut the matcher only had_catalog(private). Every price-variance check hit an AttributeError that the bare-except swallowed into a "price_variance_check_failed" reason — meaning the clean gate ALWAYS failed in production, even on perfectly clean drafts. Added a publiccatalogproperty + regression tests that prove the gate now returnsclean=Trueend-to-end and that the variance branch actually compares. - Tests: 22 new reporting tests + 3 regression tests on the clean gate. Full suite: 96 tests, all green.
v0.6.0 shipped overnight by the autonomous build May 26, 2026
Cut 2 — auto-reply draft to buyer (Gmail)
- New tool:
draft_reply_to_buyer(message_id, qb_estimate_id). After a PO is processed into a QuickBooks Estimate, the connector drafts a reply on the original Gmail thread referencing the QB Estimate number and the buyer's PO. The draft lands in your Gmail Drafts folder. You review and click send — we never send for you. - Threading is correct. Reply uses the original message's
Message-Idheader (viaIn-Reply-ToandReferences) and the same GmailthreadId, so Gmail collapses the conversation cleanly. Subject is auto-prefixed withRe:(and skips the prefix if the original already starts with "Re:"). - Template + override. Default template fills in the QB doc number, PO number, total, and a per-line summary automatically. Pass
sender_signaturefor the sign-off,salutationfor the greeting,include_lines=falseto skip the line summary, orcustom_body=...for full control over the body. - Lookup is forgiving. Pass the local
draft_idif you have it. Otherwise, the tool resolves the matching submitted draft byqb_estimate_id, then bymessage_id. Returns a clear error if no submitted draft matches. - Same conservatism as Cut 1. Draft only, never send. We never request the
gmail.sendscope — onlygmail.modify, which covers drafts.create. The buyer never sees anything until you click send in Gmail. - Tests: 26 new unit tests covering body rendering, subject prefixing, threading, all three lookup paths, the draft-not-submitted refusal, and the Gmail API failure path.
v0.5.0 shipped overnight by the autonomous build May 26, 2026
Cut 1 — auto-submit clean POs (opt-in)
- New tool:
auto_submit_if_clean(draft_id). When every line of a draft passes the clean gate, the connector submits to QuickBooks without further human review. Default: off. Enable by settingSIDEQUEST_AUTOSUBMIT=truein~/.qb-distributor-mcp/.envand re-running the env-injection one-liner. - The clean gate. A draft is "clean" only when: customer is linked to QuickBooks, every line has a real
qb_item_id, no line has a low-confidence review flag, no line price is more thanprice_variance_toleranceoff your catalog. Any failure returns{"status": "not_clean", "reasons": [...]}and the draft sits in your queue for manual review. - Conservative by design. Off by default. Even when enabled, returns "disabled" if the env var isn't set. An
override_clean_gateescape hatch exists for operator-reviewed exceptions, but is not the default path. - Tests: 22 unit tests covering the env-var gate, each clean-gate failure mode, and the structural branches (already-submitted, not-found, not-clean). Full suite passes — 59 tests green.
v0.4.0 May 25, 2026
Self-healing error messages and self-serve install
- Connector: Every tool now returns a customer-friendly error message instead of a raw Python traceback. Errors include a likely fix and a link to the diagnose prompt. Recognized patterns: missing env vars, expired QuickBooks refresh token, Gmail OAuth token revoked, customer-not-linked on submit.
- Site: New Install prompt page. Paste one block into Claude Desktop and Claude becomes your implementation specialist. About 25 minutes start to finish, no docs reading required.
- Site: New Diagnose page. Paste one block when something's broken and Claude walks you through the troubleshooting playbook. Covers seven of the most common failure modes.
- Site: New Terminal basics guide for non-technical users. Five skills, three minutes to read, Mac and Windows side by side.
- Site: New PO Time Calculator showing the annual cost of manual PO entry with your inputs.
- Mobile: Full hamburger menu drawer on every page. Previously the nav hid everything but the CTA on phones.
- SEO: Sitemap namespace fix (was rejected by Google with a one-letter typo). Now showing Success with all pages discovered.
v0.3.0 May 24, 2026
Working OAuth flow + zip rebuild
- Setup wizard: Rewrote cli.py for the actual working OAuth flow. QuickBooks now connects via Intuit's hosted OAuth Playground (the old wizard hung forever because Intuit silently rejects localhost redirect URIs).
- Gmail OAuth: Documented the "add second secret" workaround — Google's first download of client_secret.json is missing the actual secret value.
- Env injection: Setup now writes credentials directly into Claude Desktop's config env block, since the MCP server doesn't read .env from cwd.
- Docs: Full rewrite of quick-start, welcome kit, FAQ, and operator runbook to match the working flow.
v0.2.0 May 21, 2026
Marketing site online
- Launched sidequestautomation.com with quick-start, pricing, demo, and welcome kit pages.
- Stripe payment links for Starter, Growth, Scale, Unlimited tiers.
- Free tier for the first 20 POs per month with no credit card required.
What's next
Honest roadmap. No vaporware.
- QuickBooks Desktop bridge. For distributors who run QB Desktop instead of QB Online. Targeting Q3 2026.
- Direct Shopify API integration. Skip the email step for ecommerce orders. Targeting Q3 2026.
- Microsoft 365 / Outlook reader. Same shape as the Gmail reader, but for distributors on Outlook. Design doc due first.
- Structured OCR confidence. Replace the single OCR confidence score with subscores for text legibility, table structure, and quantity-vs-price disambiguation so flagged-for-review lines get a more specific reason.